

Hello Everyone! Today we are here with another post furthering our discussion about basic indexing operations in solr. The most commonly used form of data representation is JSON and XML. Today we will discuss how to handle indexing of custom JSON objects in solr. In order to do this, we use certain tags telling solr’s binary’s as to what has to be done and send them using update request. These parameters essentially handle the incoming JSON strings.One or more valid JSON documents can be sent to the /update/json/docs path with the configuration params.
Mapping Parameters
These parameters allow you to define how a JSON file should be read for multiple Solr documents.
split
Defines the path at which to split the input JSON into multiple Solr documents and is required if you have multiple documents in a single JSON file. If the entire JSON makes a single Solr document, the path must be “/”.
It is possible to pass multiple split paths by separating them with a pipe (|), for example: split=/|/hello|/hello/world. If one path is a child of another, they automatically become a child document.
f
Provides multivalued mapping to map document field names to Solr field names. The format of the parameter is target-field-name:json-path, as in f=first:/first. The json-path is required. The target-field-name is the Solr document field name, and is optional. If not specified, it is automatically derived from the input JSON. The default target field name is the fully qualified name of the field.
mapUniqueKeyOnly
(boolean) This parameter is particularly convenient when the fields in the input JSON are not available in the schema and schemaless mode is not enabled. This will index all the fields into the default search field (using the df parameter, below) and only the uniqueKey field is mapped to the corresponding field in the schema. If the input JSON does not have a value for the uniqueKey field then a UUID is generated for the same.
df
If the mapUniqueKeyOnly flag is used, the update handler needs a field where the data should be indexed to. This is the same field that other handlers use as a default search field.
srcField
This is the name of the field to which the JSON source will be stored into. This can only be used if split=/ (i.e., you want your JSON input file to be indexed as a single Solr document). (Ultram) Note that atomic updates will cause the field to be out-of-sync with the document.
echo
This is for debugging purpose only. Set it to true if you want the docs to be returned as a response. Nothing will be indexed.
For example, if we have a JSON file that includes two documents, we could define an update request like this:
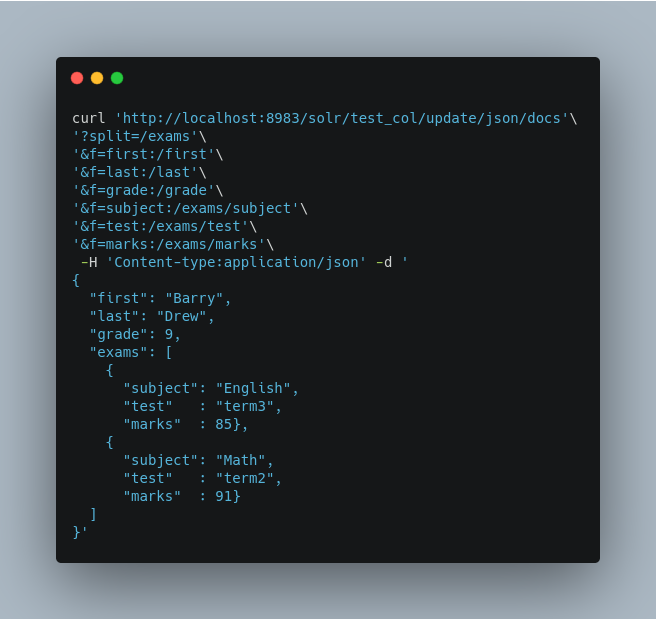
With this request, we have defined that “exams” contains multiple documents. In addition, we have mapped several fields from the input document to Solr fields.
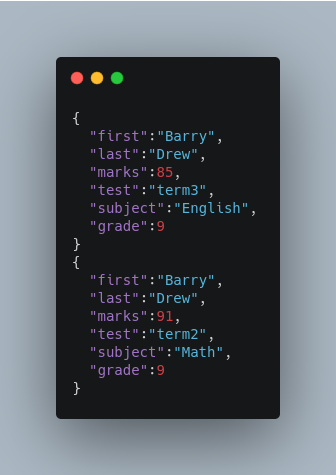
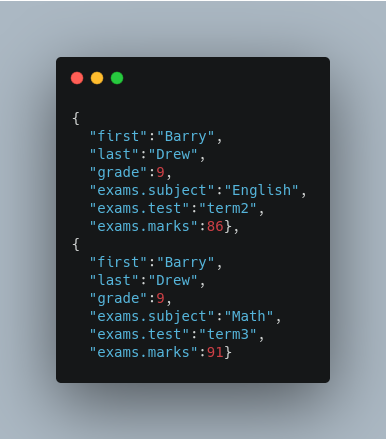
When the update request is complete, the following two documents will be added to the index:
In the prior example, all of the fields we wanted to use in Solr had the same names as they did in the input JSON. When that is the case, we can simplify the request by only specifying the json-path portion of the f parameter, as in this example:
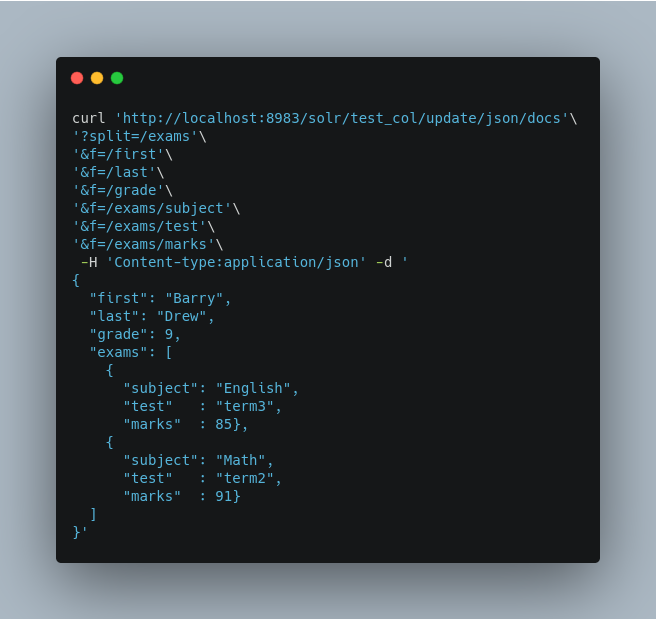
In this example, we simply named the field paths (such as /exams/test). Solr will automatically attempt to add the content of the field from the JSON input to the index in a field with the same name.
ProTip: Documents will be rejected during indexing if the fields do not exist in the schema before indexing. So, if you are NOT using schemaless mode, you must pre-create all fields.
Reusing Parameters in Multiple Requests
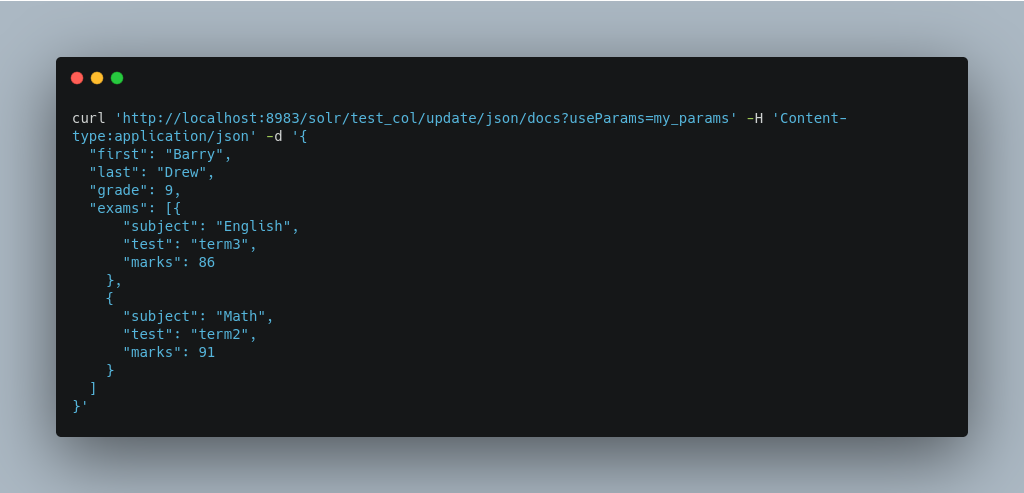
Say we wanted to define parameters to split documents at the exams field, and map several other fields. We could make an API request such as:
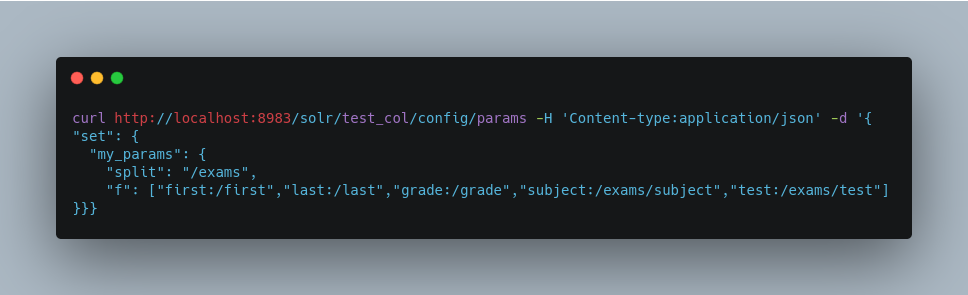
When we send the documents, we’d use the useParams parameter with the name of the parameter set we defined:
Using Wildcards for Field Names
Instead of specifying all the field names explicitly, it is possible to specify wildcards to map fields automatically.
There are two restrictions: wildcards can only be used at the end of the json-path, and the split path cannot use wildcards.
A single asterisk * maps only to direct children, and a double asterisk ** maps recursively to all descendants. The following are example wildcard path mappings:
f=$FQN:/**: maps all fields to the fully qualified name ($FQN) of the JSON field. The fully qualified name is obtained by concatenating all the keys in the hierarchy with a period (.) as a delimiter. This is the default behavior if nofpath mappings are specified.f=/docs/*: maps all the fields under docs and in the name as given in jsonf=/docs/**: maps all the fields under docs and its children in the name as given in jsonf=searchField:/docs/*: maps all fields under /docs to a single field called ‘searchField’f=searchField:/docs/**: maps all fields under /docs and its children to searchField
With wildcards we can further simplify our previous example as follows:
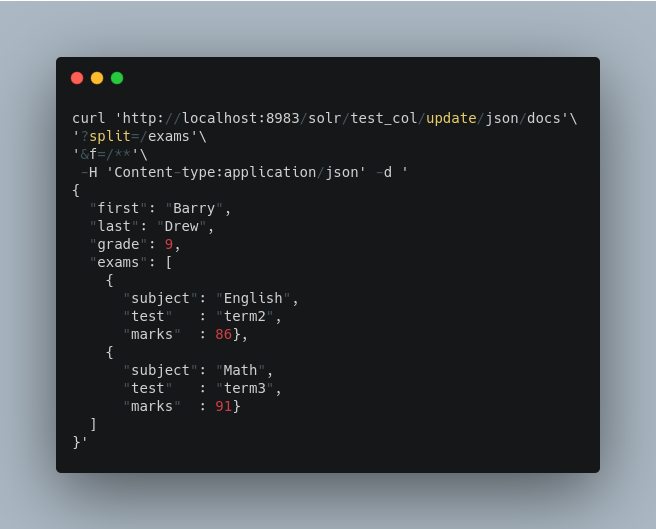
Because we want the fields to be indexed with the field names as they are found in the JSON input, the double wildcard in f=/** will map all fields and their descendants to the same fields in Solr.
It is also possible to send all the values to a single field and do a full text search on that. This is a good option to blindly index and query JSON documents without worrying about fields and schema.
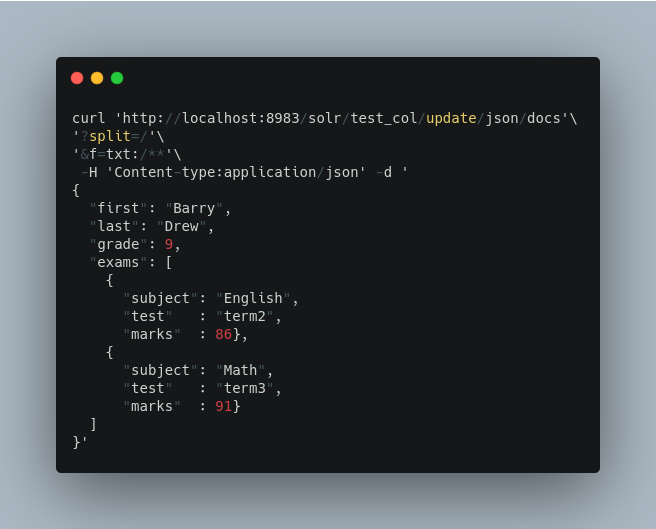
In the above example, we’ve said all of the fields should be added to a field in Solr named ‘txt’. This will add multiple fields to a single field, so whatever field you choose should be multi-valued.
The default behavior is to use the fully qualified name (FQN) of the node. So, if we don’t define any field mappings, like this:
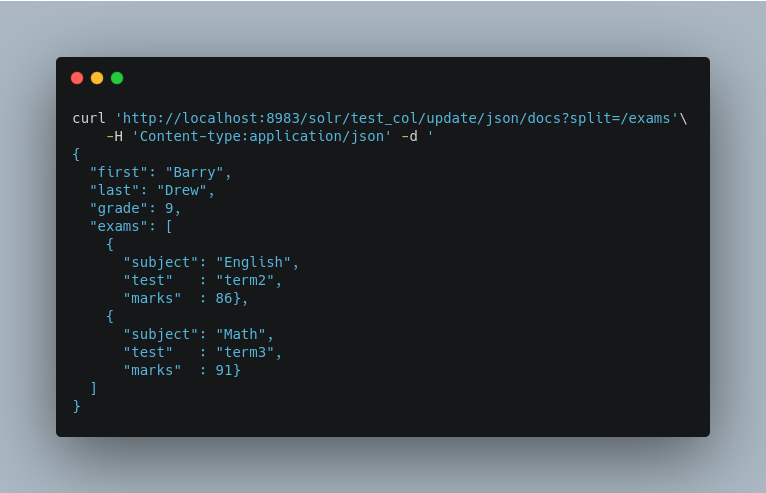
The indexed documents would be added to the index with fields that look like this:
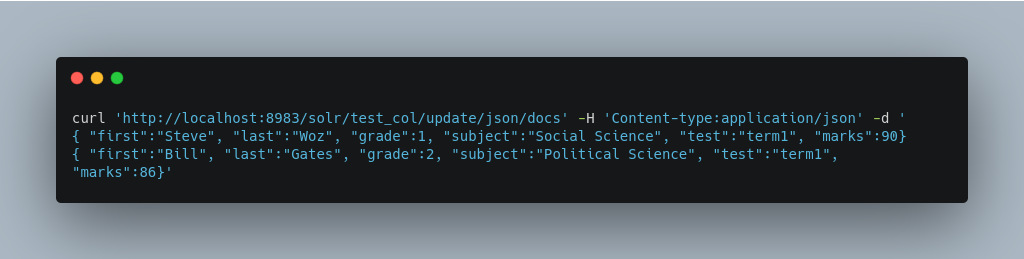
Multiple Documents in a Single Payload
This functionality supports documents in the JSON Lines format (.jsonl), which specifies one document per line.
For example:
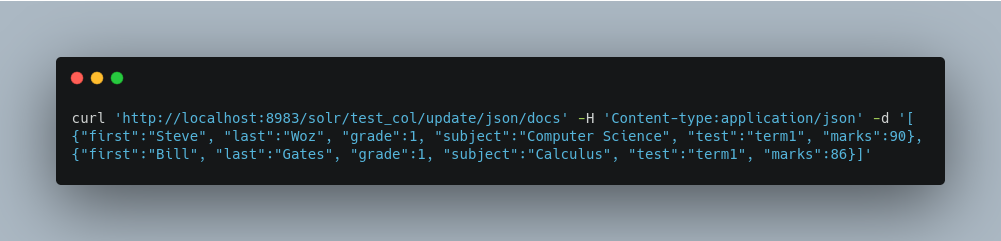
Or even an array of documents, as in this example:
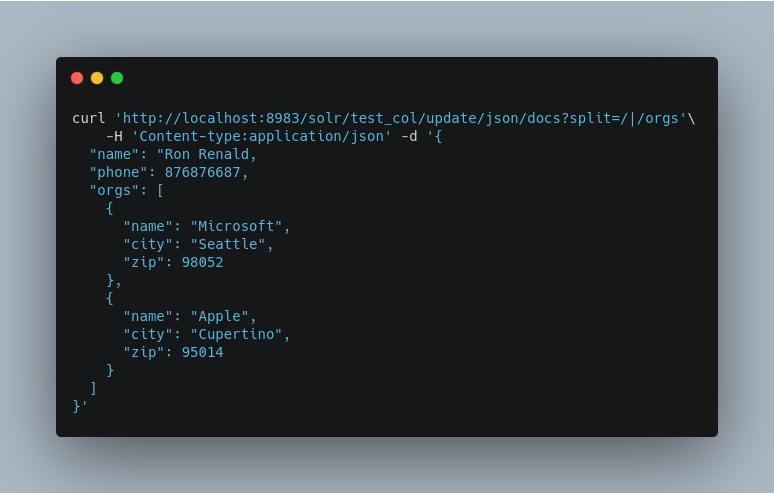
Indexing Nested Documents
The following is an example of indexing nested documents:
With this example, the documents indexed would be, as follows:

Tips to index JSON
- Pre-created Schema: Post your docs to the
/update/json/docsendpoint withecho=true. This gives you the list of field names you need to create. Create the fields before you actually index. - No schema, only full-text search: All you need to do is to do full-text search on your JSON. Set the configuration as given in the Setting JSON Defaults section.
Setting JSON Defaults
It is possible to send any JSON to the /update/json/docs endpoint and the default configuration of the component is as follows:
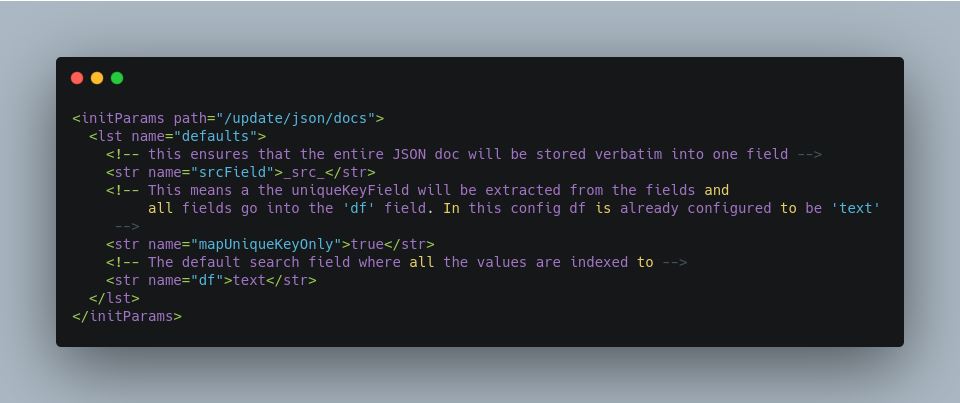
So, if no params are passed, the entire JSON file would get indexed to the _src_ field and all the values in the input JSON would go to a field named text. If there is a value for the uniqueKey it is stored and if no value could be obtained from the input JSON, a UUID is created and used as the uniqueKey field value.
So, this is it for today. Stay tuned for another post.

Manoj Kumar is a seasoned Digital Marketing Manager and passionate Tech Blogger with deep expertise in SEO, AI trends, and emerging digital technologies. He writes about innovative solutions that drive growth and transformation across industry.
Featured on – YOURSTORY | TECHSLING | ELEARNINGINDUSTRY | DATASCIENCECENTRAL | TIMESOFINDIA | MEDIUM | DATAFLOQ


