

Hi All, today I’m presenting another post on solr pertaining to language analysis. In most business applications, there comes a scenario where the business needs to deal with data in multiple languages, the most common scenario being dealing with customers of different geographies. Solr helps to deal with multiple languages in a unique way.
This section contains information about tokenizers and filters related to character set conversion or for use with specific languages.
For the European languages, tokenization is fairly straightforward. Tokens are delimited by white space and/or a relatively small set of punctuation characters.
In other languages the tokenization rules are often not so simple. Some European languages may also require special tokenization rules, such as rules for decompounding German words.
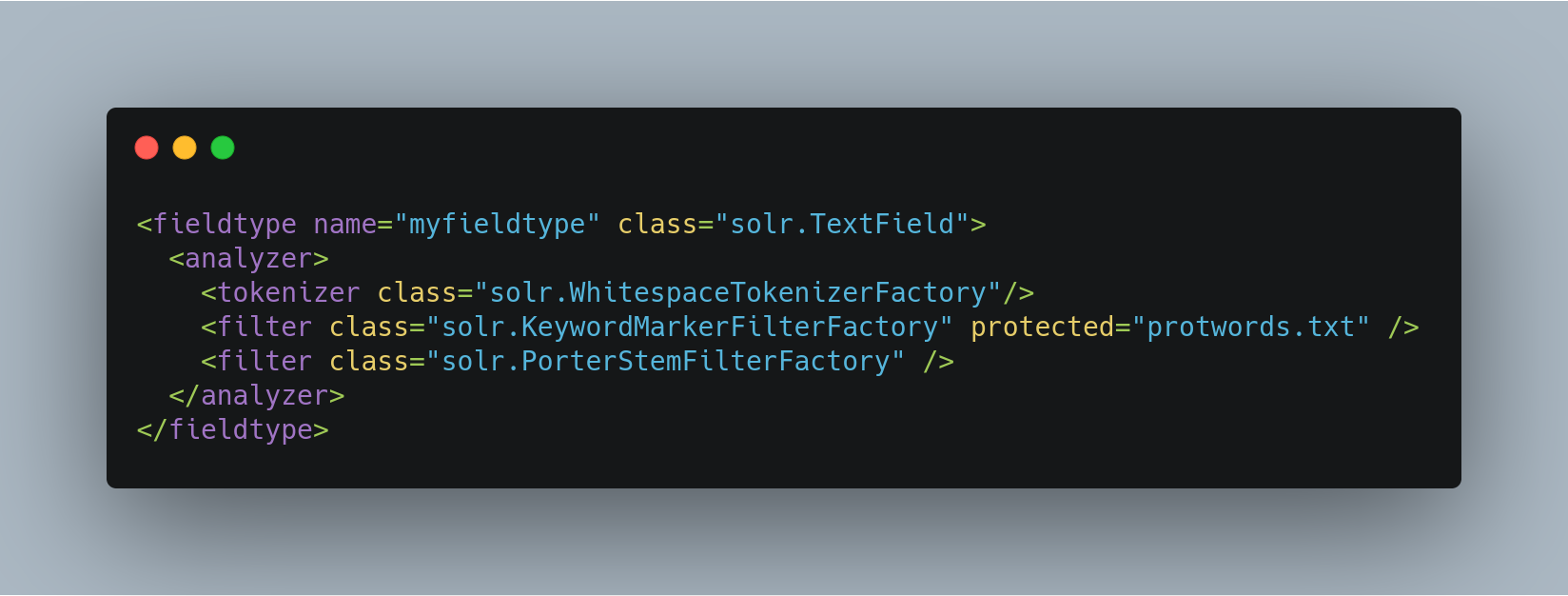
KeywordMarkerFilterFactory
Protects words from being modified by stemmers. A customized protected word list may be specified with the “protected” attribute in the schema. Any words in the protected word list will not be modified by any stemmer in Solr.
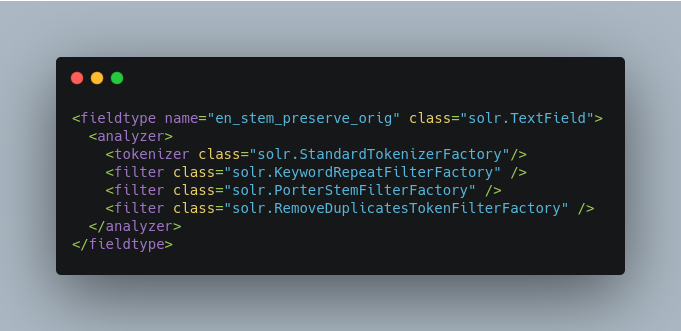
KeywordRepeatFilterFactory
Emits each token twice, one with the KEYWORD attribute and once without.
If placed before a stemmer, the result will be that you will get the unstemmed token preserved on the same position as the stemmed one. Queries matching the original exact term will get a better score while still maintaining the recall benefit of stemming. Another advantage of keeping the original token is that wildcard truncation will work as expected.
To configure, add the KeywordRepeatFilterFactory early in the analysis chain. It is recommended to also include RemoveDuplicatesTokenFilterFactory to avoid duplicates when tokens are not stemmed.
A sample fieldType configuration could look like this:
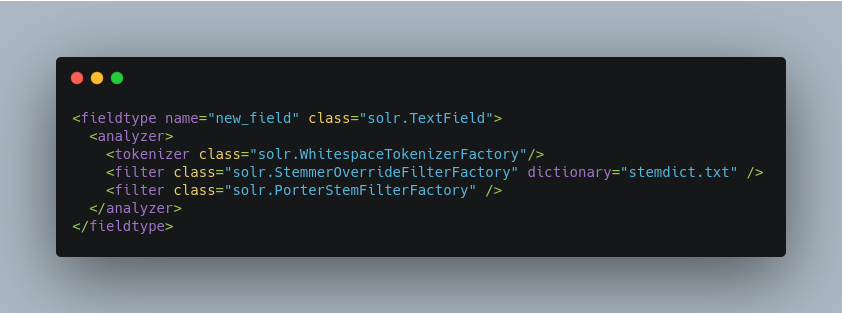
StemmerOverrideFilterFactory
Overrides stemming algorithms by applying a custom mapping, then protecting these terms from being modified by stemmers.
A customized mapping of words to stems, in a tab-separated file, can be specified to the “dictionary” attribute in the schema. Words in this mapping will be stemmed to the stems from the file, and will not be further changed by any stemmer.
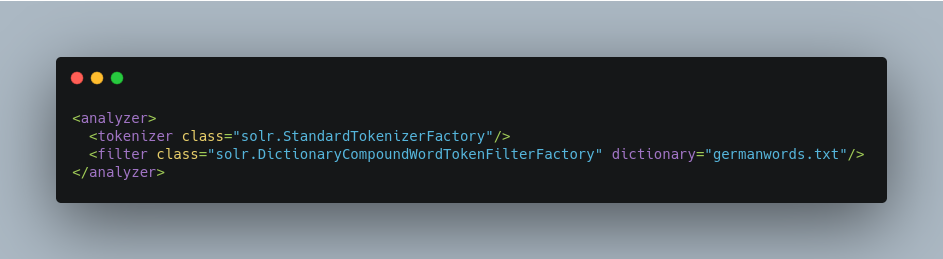
Dictionary Compound Word Token Filter
This filter splits, or decompounds, compound words into individual words using a dictionary of the component words. Each input token is passed through unchanged. If it can also be decompounded into subwords, each subword is also added to the stream at the same logical position.
Compound words are most commonly found in Germanic languages.
Factory class: solr.DictionaryCompoundWordTokenFilterFactory
Arguments:
dictionary- (required) The path of a file that contains a list of simple words, one per line. Blank lines and lines that begin with “#” are ignored. This path may be an absolute path, or path relative to the Solr config directory.
minWordSize- (integer, default 5) Any token shorter than this is not decompounded.
minSubwordSize- (integer, default 2) Subwords shorter than this are not emitted as tokens.
maxSubwordSize- (integer, default 15) Subwords longer than this are not emitted as tokens.
onlyLongestMatch- (true/false) If true (the default), only the longest matching subwords will generate new tokens.
Example:
Assume that germanwords.txt contains at least the following words: dumm kopf donau dampf schiff
In: “Donaudampfschiff dummkopf”
Tokenizer to Filter: “Donaudampfschiff”(1), “dummkopf”(2),
Out: “Donaudampfschiff”(1), “Donau”(1), “dampf”(1), “schiff”(1), “dummkopf”(2), “dumm”(2), “kopf”(2)
Unicode Collation
Unicode Collation is a language-sensitive method of sorting text that can also be used for advanced search purposes.
Unicode Collation in Solr is fast, because all the work is done at index time.
Rather than specifying an analyzer within <fieldtype … class="solr.TextField">, the solr.CollationField and solr.ICUCollationField field type classes provide this functionality. solr.ICUCollationField, which is backed by the ICU4J library, provides more flexible configuration, has more locales, is significantly faster, and requires less memory and less index space, since its keys are smaller than those produced by the JDK implementation that backs solr.CollationField.
solr.ICUCollationField is included in the Solr analysis-extras contrib – see solr/contrib/analysis-extras/README.txt for instructions on which jars you need to add to your SOLR_HOME/lib in order to use it.
solr.ICUCollationField and solr.CollationField fields can be created in two ways:
- Based upon a system collator associated with a Locale.
- Based upon a tailored
RuleBasedCollatorruleset.
Arguments for solr.ICUCollationField, specified as attributes within the <fieldtype> element:
Using a System collator:
locale- (required) RFC 3066 locale ID. See the ICU locale explorer for a list of supported locales.
strength- Valid values are
primary,secondary,tertiary,quaternary, oridentical. See Comparison Levels in ICU Collation Concepts for more information. decomposition- Valid values are
noorcanonical. See Normalization in ICU Collation Concepts for more information.
Using a Tailored ruleset:
custom- (required) Path to a UTF-8 text file containing rules supported by the ICU
RuleBasedCollator strength- Valid values are
primary,secondary,tertiary,quaternary, oridentical. See Comparison Levels in ICU Collation Concepts for more information. decomposition- Valid values are
noorcanonical. See Normalization in ICU Collation Concepts for more information.
Expert options:
alternate- Valid values are
shiftedornon-ignorable. Can be used to ignore punctuation/whitespace. caseLevel- (true/false) If true, in combination with
strength="primary", accents are ignored but case is taken into account. The default is false. See CaseLevel in ICU Collation Concepts for more information. caseFirst- Valid values are
lowerorupper. Useful to control which is sorted first when case is not ignored. numeric- (true/false) If true, digits are sorted according to numeric value, e.g. foobar-9 sorts before foobar-10. The default is false.
variableTop- Single character or contraction. Controls what is variable for
alternate.

Manoj Kumar is a seasoned Digital Marketing Manager and passionate Tech Blogger with deep expertise in SEO, AI trends, and emerging digital technologies. He writes about innovative solutions that drive growth and transformation across industry.
Featured on – YOURSTORY | TECHSLING | ELEARNINGINDUSTRY | DATASCIENCECENTRAL | TIMESOFINDIA | MEDIUM | DATAFLOQ



