

Hello everyone! We are back with another post. This time we will discuss in detail an important aspect affecting a large number of enterprise applications. Let’s face it, in today’s fast-changing world, if an organization doesn’t keep abreast with the much-needed changes in their core systems, it is quickly forgotten and it tends to lose customers very fast. Eventually, competitors gain the edge which ultimately leads to revenue losses.
Take, for example, a big retail-based enterprise. It is managing its business using a fine-tuned legacy system Oracle ATG. We know that oracle ATG is used in a lot of enterprises around the globe and has cemented its position over the course of time. It has Endeca as a core search engine that has gotten obsolete over time. While the competition continued to grow and expand its technical capabilities, the changes in Endeca have not been so steep, to say the least. On many occasions, responses did not sync with the keyword searched and features like visual search, relevancy, user-centric personalization were not implemented which today’s user mostly wants.
Modern search engines, however, provide the above-mentioned features and can thus be used as a modern replacement. This not only improves conversion rates for any retail business but also positively impacts revenue by a search.
What To Expect From a Modern Search Engine?
- Ability to predict user query based on historical data
- Give personalized suggestions to each user balancing the business needs and user demands.
- Making the indexing process easy to handle, providing support for diverse data sources, mitigating risk for data loss, etc.
- Features like smart suggestion, visual search
Overview
This blog post will cover the following aspects w.r.t building a customizable search engine.
- Why Solr is better suited to handle search traffic in today’s time.
- How to migrate from the black-box styled old system to cloud-deployed search engines like Apache Solr
- What to expect after re-platforming to Solr
A good search characteristics
Before jumping to the process of migration to Solr cloud, let’s understand what constitutes a good browsing experience. This is essentially a set of features that directly impact customer experience and facilitates improving the merchandising team’s work efficiency. Another important aspect here is to fully understand the user’s intent.
Getting User’s Intent
A good search engine has the capability of understanding user queries at a deep level so that most relevant results can be shown to users. Some features which ensure a search engine to be successful are as follows:
- Natural Language Processing (NLP): Though intuitive, it’s a little challenging for making a search engine understand the user queries at a deep, semantic level. Fortunately, there are multiple open-source libraries that can help achieve this task. For example, searching “new headphones under $300” is different from searching “bose headphones on sale under $100”. In each case, individual terms should be mapped to different attributes which in turn connect to different products.
- Improving relevancy in real-time: If the customer’s search is very specific, this might lead to a reflection of only a few results from the entire catalog. This prevents the search engine to show more “relevant” products from inventory, hence, a search engine must be smart enough to reflect more products from the catalog which closely resemble the queried terms.
- Semantic Search: The role of a search engine is to correctly map each term in the query to correct attribute. This is hard as a word holds multiple meanings in the same language. For example, in the “french band shirt” and “french hair band”, “band” has different meanings. The good news is that we currently have a technology that understands these semantics which can be implemented based on unique business needs. We will cover a detailed post about this topic sometime later.
- Understanding of retail language: Many times users may search for things that are not available in the index. Instead of showing a blank page, a well-configured search engine must return results based on domain-specific linguistics or recommend different products.
- Understanding inventory and pricing: A search engine must be capable enough to keep a regular update on inventory information, pricing, discounts, etc. It is important because reflecting outdated information might lead to frustration on the payments page for the customer and might land the retailer in legal trouble.
Managing personalization of results
A very important aspect of a modern-day search engine is to give personalized results. An important aspect related to this is “boosting results”.
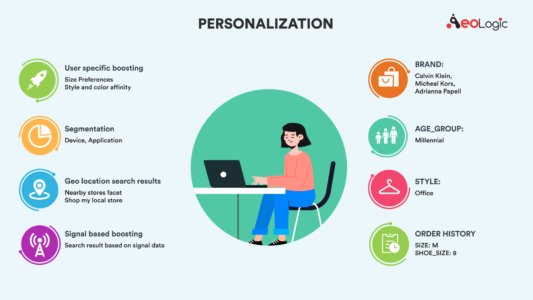
When it comes to personalized boosting, it’s not about what to show or hide but rather configuring the order of results. This implicitly demands a segment level understanding of a user along with some hidden information that impacts the result’s ordering. This, however, comes at a cost. This increases the memory demands in the server, thereby, making it challenging to scale the systems.
Another way we can impact result ordering is by using signals data. The signals can be based on anything, newness, popularity and can be enforced based on business needs. This method, however, is less user-specific and mostly implemented using general level rules in a search engine.
What do merchandisers want?
In essence, all merchandisers need a set of features to easily and effectively manage business needs.

Rules act as a powerful triggering mechanism. Something like search keywords, search context, etc can be used as a tool to trigger certain responses. This can be used by merchandisers to promote certain products based on their needs. At any given time, a search engine should be able to explain exactly why a particular product either matched or didn’t match the query, and why a matched product was ranked in a particular way. Essentially, the rules should be easily explainable and transparent. Also, any need to change the rules must be dealt with in an orderly manner, wherein, after the change merchandisers can view the effect of their change before implementing it on the production environment.
Analytics is another important aspect of merchandisers. At any given moment, the merchandiser must be able to tell as to what products are most searched, how a data point is reflected against another metric, so on and so forth. Last but not least, a modern search engine should scale to multi-channel catalog sizes and traffic, provide high performance, support cloud deployment, and maintain and operate in production easily.
How Solr fares against other search options?
Being open-source, current libraries of Solr are constantly being updated for new features. It has a transparent approach and implementation methodologies making it a good choice against other search engines.
- Solr supports multi-channel capabilities. Data from different sources can be indexed in a fast-paced environment.
- It supports a near-real-time search
- Solr is cloud-friendly, hence, Solr applications are highly fault-tolerant and support distributed index.
- Solr supports some decent level of personalization by using boosting.
How do we migrate to Solr?
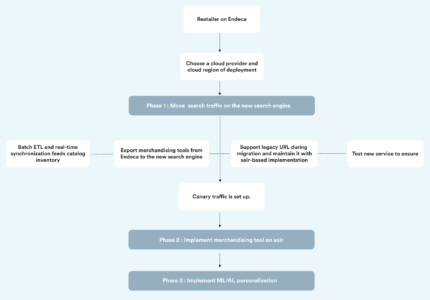
Let’s assume for this post that a retailer is using Oracle ATG platform with Endeca as its core search engine and the new search engine is based on Apache Solr. The goal here is to get the production search traffic from Endeca to the new search engine in the cloud, without negatively affecting customer experience and business aspects. Some advanced functionality, like ML/AI, NLP search and visual search can be pushed to the future phases once the foundation and core search is ready. However, some features that were not possible in Endeca – a multi-channel catalog for instance and near real-time inventory update handling can be implemented in the first phase itself as a part of the core search support.
Once the decision of which cloud platform to use is taken care of, we can begin to set up search service via a cloud platform. Here, special care has to be taken into account for latency between the data center and the cloud region. For example, if the current data center lies due east, cloud regions must also be in the east. With proper network configuration, the overhead for latency will not exceed 10-20 ms, which will be compensated by the lower latency of the Solr-based search service.
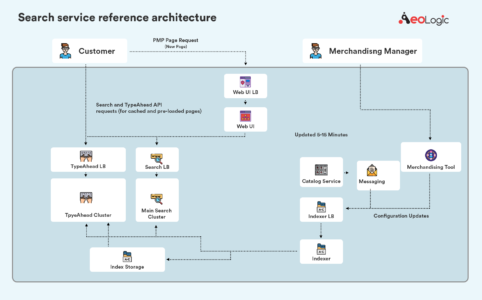
Once the cloud infrastructure is set up, the development of the new service can start. In parallel with the development of the new search service, integration logic in ATG needs to be developed to call the new service instead of Endeca. Batch ETL jobs and real-time synchronization mechanisms must be set up to feed the catalog, inventory, pricing, offers, and promotions to the search engine in the cloud. At this stage, a separate synchronization mechanism should be implemented to export merchandising rules from the Endeca experience manager and import them to the new search engine. With enough knowledge of Solr and understanding of the format of the rules, this conversion can be implemented relatively easily. The new architecture of the legacy ATG platform working with the Solr can be seen in the following infographic:
Before migrating production traffic to the new service, two important actions must be taken. First, legacy URL structure is already configured for search and browse pages, so changing the structure at this point will negatively affect SEO. Thus, the legacy URL structure must be supported while the migration is taking place and Solr-based implementation needs to be expanded to maintain this structure. Second, the new service will need to be extensively tested for search relevance to ensure consistent or better customer experience after the switch. This is accomplished in the following ways:
- Automated relevancy testing: The development and QA team can implement a set of tests to check the correlation of new and old search results.
- In-house exploratory testing: The top 100 search queries can be selected based on historical search logs, and then checked by business users and QA team to ensure relevancy.
- Crowd exploratory testing: Crowd outsourcing services can be used to test the relevancy of long-tail queries for the top 1000 or 10000 queries based on search history.
Once search tuning is done, canary traffic can be sent to the new service. At this point, site analytics tools should be set up properly to measure the effect of the canary release. If the canary release goes well, full traffic can be switched to the new search service. The whole process end-to-end usually takes several months from inception to production.
So, this is it about Re-platforming search to solr. We will be back with another post on solr very soon.

Manoj Kumar is a seasoned Digital Marketing Manager and passionate Tech Blogger with deep expertise in SEO, AI trends, and emerging digital technologies. He writes about innovative solutions that drive growth and transformation across industry.
Featured on – YOURSTORY | TECHSLING | ELEARNINGINDUSTRY | DATASCIENCECENTRAL | TIMESOFINDIA | MEDIUM | DATAFLOQ



