

Hello everyone! We are back with another post. For any enterprise-grade application, it’s very important to have fault tolerance and high availability. In many ways, it holds the key to market perception and customer satisfaction. In essence, Apache Solr includes the ability to set up a cluster of Solr servers that combines fault tolerance and high availability. Called SolrCloud, these capabilities provide distributed indexing and search capabilities, supporting the following features:
- Central configuration for the entire cluster
- Automatic load balancing and fail-over for queries
- ZooKeeper integration for cluster coordination and configuration.
SolrCloud is a flexible distributed search and indexing, without a master node to allocate nodes, shards, and replicas. Instead, Solr uses ZooKeeper to manage these locations, depending on configuration files and schemas. Queries and updates can be sent to any server. Solr will use the information in the ZooKeeper database to figure out which servers need to handle the request.
SolrCloud Basics
SolrCloud is designed to provide a highly available, fault-tolerant environment for distributing your indexed content and query requests across multiple servers.
It’s a system in which data is organized into multiple pieces, or shards, that can be hosted on multiple machines, with replicas providing redundancy for both scalability and fault tolerance, and a ZooKeeper server that helps manage the overall structure so that both indexing and search requests can be routed properly.
Getting started with Solr Cloud
Some basic commands are as follows:
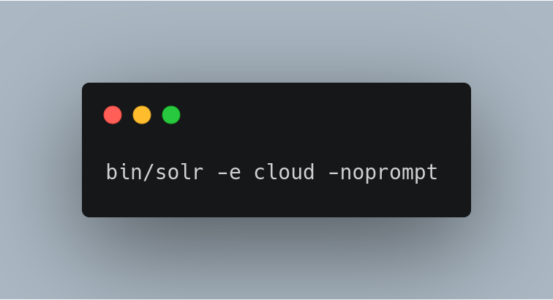
Starting with -noprompt
You can also get SolrCloud started with all the defaults instead of the interactive session using the following command:
Restarting Nodes
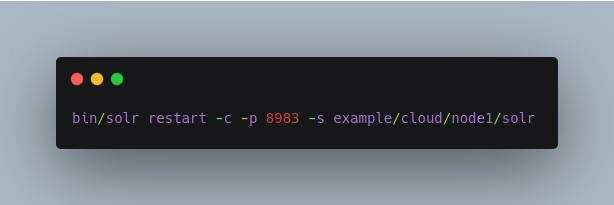
You can restart your SolrCloud nodes using the bin/solr script.
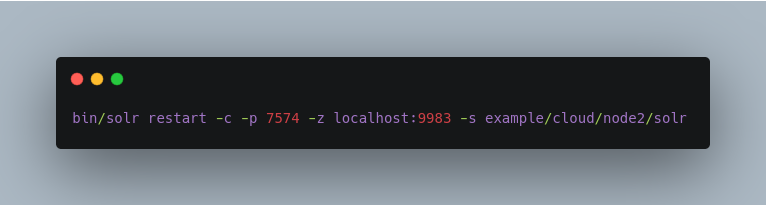
To restart node2 running on port 7574, you can do:
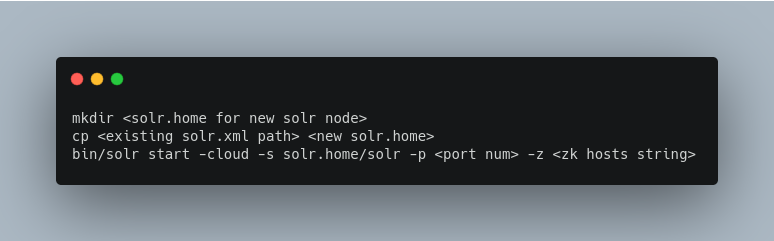
Adding a node to a cluster
Adding a node to an existing cluster is a bit advanced and involves a little more understanding of Solr.
How SolrCloud Works
A SolrCloud cluster consists of some “logical” concepts layered on top of some “physical” concepts.
Logical
- A Cluster can host multiple Collections of Solr Documents.
- A collection can be partitioned into multiple Shards, which contain a subset of the Documents in the Collection.
- The number of Shards that a Collection has determines:
- The theoretical limit to the number of Documents that Collection can reasonably contain.
- The amount of parallelization that is possible for an individual search request.
Physical
- A Cluster is made up of one or more Solr Nodes, which are running instances of the Solr server process.
- Each Node can host multiple Cores.
- Each Core in a Cluster is a physical Replica for a logical Shard.
- Every Replica uses the same configuration specified for the Collection that it is a part of.
- The number of Replicas that each Shard has determines:
- The level of redundancy built into the Collection and how fault tolerant the Cluster can be in the event that some Nodes become unavailable.
- The theoretical limit in the number concurrent search requests that can be processed under heavy load.
When the collection is too large for one node, you can break it up and store it in sections by creating multiple shards. A Shard is a logical partition of the collection, containing a subset of documents from the collection, such that every document in a collection is contained in exactly one Shard. Which shard contains each document in a collection depends on the overall “Sharding” strategy for that collection. For example, you might have a collection where the “country” field of each document determines which shard it is part of, so documents from the same country are co-located. A different collection might simply use a “hash” on the uniqueKey of each document to determine its Shard.
Before SolrCloud, Solr supported Distributed Search, which allowed one query to be executed across multiple shards, so the query was executed against the entire Solr index and no documents would be missed from the search results. So splitting an index across shards is not exclusively a SolrCloud concept. There were, however, several problems with the distributed approach that necessitated improvement with SolrCloud:
- Splitting an index into shards was somewhat manual.
- There was no support for distributed indexing, which meant that you needed to explicitly send documents to a specific shard; Solr couldn’t figure out on its own what shards to send documents to.
- There was no load balancing or failover, so if you got a high number of queries, you needed to figure out where to send them and if one shard died it was just gone.
SolrCloud fixes all those problems. There is support for distributing both the index process and the queries automatically, and ZooKeeper provides failover and load balancing. Additionally, every shard can also have multiple replicas for additional robustness.
In SolrCloud there are no masters or slaves. Instead, every shard consists of at least one physical replica, exactly one of which is a leader. Leaders are automatically elected, initially on a first-come-first-served basis, and then based on the ZooKeeper process described.
If a leader goes down, one of the other replicas is automatically elected as the new leader.
When a document is sent to a Solr node for indexing, the system first determines which Shard that document belongs to, and then which node is currently hosting the leader for that shard. The document is then forwarded to the current leader for indexing, and the leader forwards the update to all of the other replicas.
Document Routing: Solr offers the ability to specify the router implementation used by a collection by specifying the router.name parameter when creating your collection.
If you use the (default) “compositeId” router, you can send documents with a prefix in the document ID which will be used to calculate the hash Solr uses to determine the shard a document is sent to for indexing. The prefix can be anything you’d like it to be (it doesn’t have to be the shard name, for example), but it must be consistent so Solr behaves consistently. For example, if you wanted to co-locate documents for a customer, you could use the customer name or ID as the prefix. If your customer is “IBM”, for example, with a document with the ID “12345”, you would insert the prefix into the document id field: “IBM!12345”. The exclamation mark (‘!’) is critical here, as it distinguishes the prefix used to determine which shard to direct the document to. If you do not want to influence how documents are stored, you don’t need to specify a prefix in your document ID.
Shard Splitting: When you create a collection in SolrCloud, you decide on the initial number shards to be used. But it can be difficult to know in advance the number of shards that you need, particularly when organizational requirements can change at a moment’s notice, and the cost of finding out later that you chose wrong can be high, involving creating new cores and re-indexing all of your data. The ability to split shards is in the Collections API. It currently allows splitting a shard into two pieces. The existing shard is left as-is, so the split action effectively makes two copies of the data as new shards. You can delete the old shard at a later time when you’re ready.
In most cases, when running in SolrCloud mode, indexing client applications should not send explicit commit requests. Rather, you should configure auto commits with openSearcher=false and auto soft-commits to make recent updates visible in search requests. This ensures that auto commits occur on a regular schedule in the cluster.
Ignoring commits from Client Applications: To enforce a policy where client applications should not send explicit commits, you should update all client applications that index data into SolrCloud. However, that is not always feasible, so Solr provides the IgnoreCommitOptimizeUpdateProcessorFactory, which allows you to ignore explicit commits and/or optimize requests from client applications without having refactored your client application code. To activate this request processor you’ll need to add the following to your solrconfig.xml:
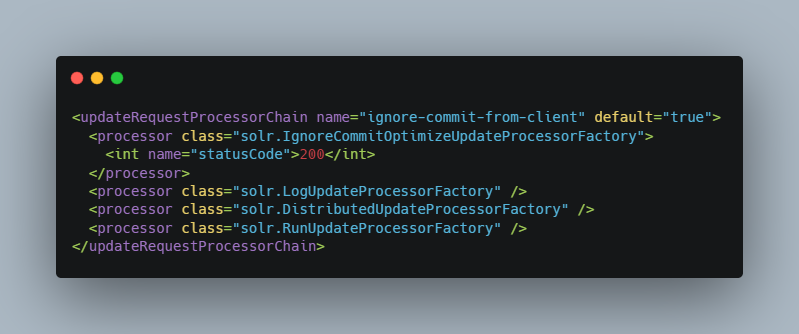
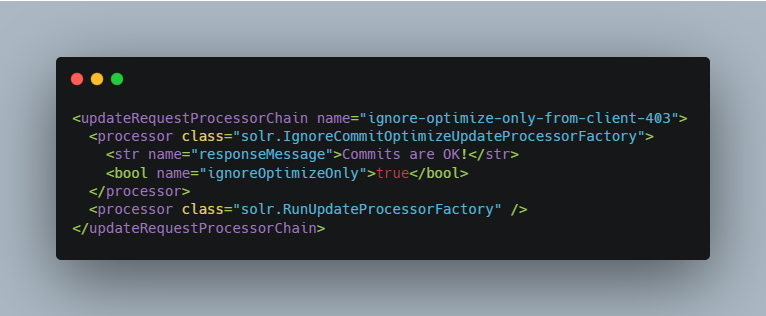
Distributed Requests:
When a Solr node receives a search request, the request is routed behind the scenes to a replica of a shard that is part of the collection being searched.
The chosen replica acts as an aggregator: it creates internal requests to randomly chosen replicas of every shard in the collection, coordinates the responses, issues any subsequent internal requests as needed (for example, to refine facets values, or request additional stored fields), and constructs the final response for the client.
So, this is it about cloud implementation in solr. We will be back with another post on solr very soon.

Manoj Kumar is a seasoned Digital Marketing Manager and passionate Tech Blogger with deep expertise in SEO, AI trends, and emerging digital technologies. He writes about innovative solutions that drive growth and transformation across industry.
Featured on – YOURSTORY | TECHSLING | ELEARNINGINDUSTRY | DATASCIENCECENTRAL | TIMESOFINDIA | MEDIUM | DATAFLOQ



