

Introduction
Hello everyone! We are back with another post. Today we will discuss in detail another important aspect used in many enterprise-grade applications. All organizations big and small in evidently store data some form of structured data store. Data import handler provides a mechanism for importing content of that datastore and indexing it. In addition to it, there can be HTTP/RSS based data store along with ATOM feeds, email repositories, structures XML, so on and so forth.
How DIH is configured?
DIH handler is ideally configured in solrconfig.xml. The handler configuration itself is easy and demands less work. However, when implementing with varied types of data stores, the intrinsic complexity of it becomes pretty evident. For instance, Data Import Handler can be configured as follows :
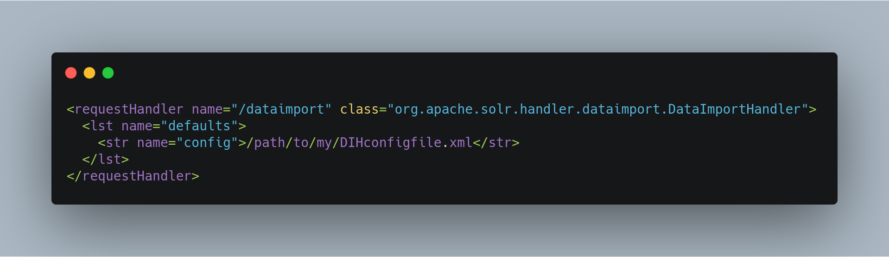
The config file here defines the information like, how to fetch data, what to fetch, the document structure conceived etc. The below example shows how to extract fields from four tables defining a simple product database. More information about the parameters and options shown here will be described in the sections following :
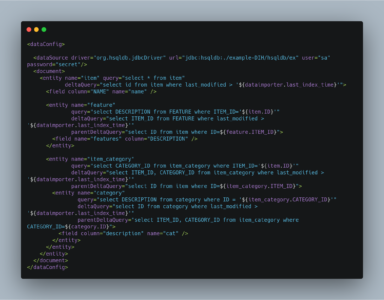
- The first element is the
dataSource, in this case an HSQLDB database. The path to the JDBC driver and the JDBC URL and login credentials are all specified here. Other permissible attributes include whether or not to autocommit to Solr, the batchsize used in the JDBC connection, and areadOnlyflag. The password attribute is optional if there is no password set for the DB. - Alternately the password can be encrypted as follows. This is the value obtained as a result of the command
openssl enc -aes-128-cbc -a -salt -in pwd.txt password="U2FsdGVkX18QMjY0yfCqlfBMvAB4d3XkwY96L7gfO2o=". When the password is encrypted, you must provide an extra attributeencryptKeyFile="/location/of/encryptionkey". This file should a text file with a single line containing the encrypt/decrypt password. - A
documentelement follows, containing multipleentityelements. Note thatentityelements can be nested, and this allows the entity relationships in the sample database to be mirrored here, so that we can generate a denormalized Solr record which may include multiple features for one item, for instance. - The possible attributes for the
entityelement are described in later sections. Entity elements may contain one or morefieldelements, which map the data source field names to Solr fields, and optionally specify per-field transformations. This entity is therootentity. - This entity is nested and reflects the one-to-many relationship between an item and its multiple features. Note the use of variables;
${item.ID}is the value of the column ‘ID’ for the current item (itemreferring to the entity name).
Datasources can still be specified in solrconfig.xml. These must be specified in the defaults section of the handler in solrconfig.xml. However, these are not parsed until the main configuration is loaded.
The entire configuration itself can be passed as a request parameter using the dataConfig parameter rather than using a file. When configuration errors are encountered, the error message is returned in XML format.
A reload-config command is also supported, which is useful for validating a new configuration file, or if you want to specify a file, load it, and not have it reloaded again on import. If there is an xml mistake in the configuration a user-friendly message is returned in xml format. You can then fix the problem and do a reload-config.
Important Commands
- abort
- Aborts an ongoing operation. For example:
http://localhost:8983/solr/dih/dataimport?command=abort. - delta-import
- For incremental imports and change detection. Only the SqlEntityProcessor supports delta imports.
For example:
http://localhost:8983/solr/dih/dataimport?command=delta-import.This command supports the same
clean,commit,optimizeanddebugparameters asfull-importcommand described below. - full-import
- A Full Import operation can be started with a URL such as
http://localhost:8983/solr/dih/dataimport?command=full-import. The command returns immediately.The operation will be started in a new thread and the status attribute in the response should be shown as busy. The operation may take some time depending on the size of dataset. Queries to Solr are not blocked during full-imports.
When a
full-importcommand is executed, it stores the start time of the operation in a file located atconf/dataimport.properties. This stored timestamp is used when adelta-importoperation is executed.Commands available to
full-importare:- clean
- Default is true. Tells whether to clean up the index before the indexing is started.
- commit
- Default is true. Tells whether to commit after the operation.
- debug
- Default is false. Runs the command in debug mode and is used by the interactive development mode.
Note that in debug mode, documents are never committed automatically. If you want to run debug mode and commit the results too, add
commit=trueas a request parameter. - entity
- The name of an entity directly under the
<document>tag in the configuration file. Use this to execute one or more entities selectively.Multiple “entity” parameters can be passed on to run multiple entities at once. If nothing is passed, all entities are executed.
- optimize
- Default is true. Tells Solr whether to optimize after the operation.
- synchronous
- Blocks request until import is completed. Default is false.
- reload-config
- If the configuration file has been changed and you wish to reload it without restarting Solr, run the command
http://localhost:8983/solr/dih/dataimport?command=reload-config - status
- This command returns statistics on the number of documents created, deleted, queries run, rows fetched, status, and so on. For example:
http://localhost:8983/solr/dih/dataimport?command=status. - show–config
- This command responds with configuration:
http://localhost:8983/solr/dih/dataimport?command=show-config.
Some Important Processors
Entity processors extract data, transform it, and add it to a Solr index. Examples of entities include views or tables in a data store.
Each processor has its own set of attributes, described in its own section below. In addition, there are several attributes common to all entities which may be specified:
- dataSource
- The name of a data source. If there are multiple data sources defined, use this attribute with the name of the data source for this entity.
- name
- Required. The unique name used to identify an entity.
- pk
- The primary key for the entity. It is optional, and required only when using delta-imports. It has no relation to the uniqueKey defined in
schema.xmlbut they can both be the same.This attribute is mandatory if you do delta-imports and then refer to the column name in
${dataimporter.delta.<column-name>}which is used as the primary key. - processor
- Default is SqlEntityProcessor. Required only if the datasource is not RDBMS.
- onError
- Defines what to do if an error is encountered.
Permissible values are:
- abort
- Stops the import.
- skip
- Skips the current document.
- continue
- Ignores the error and processing continues.
- preImportDeleteQuery
- Before a
full-importcommand, use this query this to cleanup the index instead of using*:*. This is honored only on an entity that is an immediate sub-child of<document>. - postImportDeleteQuery
- Similar to
preImportDeleteQuery, but it executes after the import has completed. - rootEntity
- By default the entities immediately under
<document>are root entities. If this attribute is set to false, the entity directly falling under that entity will be treated as the root entity (and so on). For every row returned by the root entity, a document is created in Solr. - transformer
- Optional. One or more transformers to be applied on this entity.
- cacheImpl
- Optional. A class (which must implement
DIHCache) to use for caching this entity when doing lookups from an entity which wraps it. Provided implementation isSortedMapBackedCache. - cacheKey
- The name of a property of this entity to use as a cache key if
cacheImplis specified. - cacheLookup
- An entity + property name that will be used to lookup cached instances of this entity if
cacheImplis specified. - where
- An alternative way to specify
cacheKeyandcacheLookupconcatenated with ‘=’.For example,
where="CODE=People.COUNTRY_CODE"is equivalent tocacheKey="CODE" cacheLookup="People.COUNTRY_CODE" - child=”true”
- Enables indexing document blocks aka Nested Child Documents for searching with Block Join Query Parsers. It can be only specified on the
<entity>element under another root entity. It switches from default behavior (merging field values) to nesting documents as children documents.Note: parent
<entity>should add a field which is used as a parent filter in query time. - join=”zipper”
- Enables merge join, aka “zipper” algorithm, for joining parent and child entities without cache. It should be specified at child (nested)
<entity>. It implies that parent and child queries return results ordered by keys, otherwise it throws an exception. Keys should be specified either withwhereattribute or withcacheKeyandcacheLookup.
The SQL Entity Processor
The SqlEntityProcessor is the default processor. The associated JdbcDataSource should be a JDBC URL.
The entity attributes specific to this processor are shown in the table below. These are in addition to the attributes common to all entity processors described above.
- query
- Required. The SQL query used to select rows.
- deltaQuery
- SQL query used if the operation is delta-import. This query selects the primary keys of the rows which will be parts of the delta-update. The pks will be available to the deltaImportQuery through the variable
${dataimporter.delta.<column-name>}. - parentDeltaQuery
- SQL query used if the operation is
delta-import. - deletedPkQuery
- SQL query used if the operation is
delta-import. - deltaImportQuery
- SQL query used if the operation is
delta-import. If this is not present, DIH tries to construct the import query by (after identifying the delta) modifying the ‘query’ (this is error prone).There is a namespace
${dataimporter.delta.<column-name>}which can be used in this query. For example,select * from tbl where id=${dataimporter.delta.id}.
The XPathEntityProcessor
This processor is used when indexing XML formatted data. The data source is typically URLDataSource or FileDataSource. XPath can also be used with the FileListEntityProcessor described below, to generate a document from each file.
The entity attributes unique to this processor are shown below. These are in addition to the attributes common to all entity processors described above.
- Processor
- Required. Must be set to
XpathEntityProcessor. - url
- Required. The HTTP URL or file location.
- stream
- Optional: Set to true for a large file or download.
- forEach
- Required unless you define
useSolrAddSchema. The XPath expression which demarcates each record. This will be used to set up the processing loop. - xsl
- Optional: Its value (a URL or filesystem path) is the name of a resource used as a preprocessor for applying the XSL transformation.
- useSolrAddSchema
- Set this to true if the content is in the form of the standard Solr update XML schema.
Each <field> element in the entity can have the following attributes as well as the default ones.
- xpath
- Required. The XPath expression which will extract the content from the record for this field. Only a subset of XPath syntax is supported.
- commonField
- Optional. If true, then when this field is encountered in a record it will be copied to future records when creating a Solr document.
- flatten
- Optional. If set to true, then any children text nodes are collected to form the value of a field.
The TikaEntityProcessor
The TikaEntityProcessor uses Apache Tika to process incoming documents. This is similar to Uploading Data with Solr Cell using Apache Tika, but using DataImportHandler options instead.
The parameters for this processor are described in the table below. These are in addition to the attributes common to all entity processors described above.
- dataSource
- This parameter defines the data source and an optional name which can be referred to in later parts of the configuration if needed. This is the same
dataSourceexplained in the description of general entity processor attributes above.The available data source types for this processor are:
- BinURLDataSource: used for HTTP resources, but can also be used for files.
- BinContentStreamDataSource: used for uploading content as a stream.
- BinFileDataSource: used for content on the local filesystem.
- url
- Required. The path to the source file(s), as a file path or a traditional internet URL.
- htmlMapper
- Optional. Allows control of how Tika parses HTML. If this parameter is defined, it must be either default or identity; if it is absent, “default” is assumed.
The “default” mapper strips much of the HTML from documents while the “identity” mapper passes all HTML as-is with no modifications.
- format
- The output format. The options are text, xml, html or none. The default is “text” if not defined. The format “none” can be used if metadata only should be indexed and not the body of the documents.
- parser
- Optional. The default parser is
org.apache.tika.parser.AutoDetectParser. If a custom or other parser should be used, it should be entered as a fully-qualified name of the class and path. - fields
- The list of fields from the input documents and how they should be mapped to Solr fields. If the attribute
metais defined as “true”, the field will be obtained from the metadata of the document and not parsed from the body of the main text. - extractEmbedded
- Instructs the TikaEntityProcessor to extract embedded documents or attachments when true. If false, embedded documents and attachments will be ignored.
- onError
- By default, the TikaEntityProcessor will stop processing documents if it finds one that generates an error. If you define
onErrorto “skip”, the TikaEntityProcessor will instead skip documents that fail processing and log a message that the document was skipped.For Example :
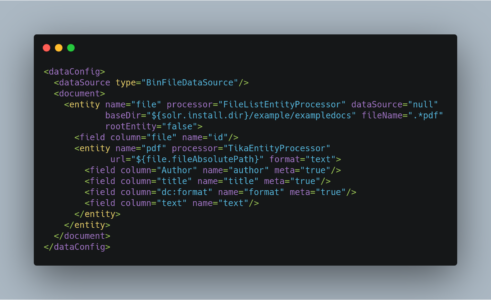
So, this is it about Data import handler solr. We will be back with another post on solr very soon.

Manoj Kumar is a seasoned Digital Marketing Manager and passionate Tech Blogger with deep expertise in SEO, AI trends, and emerging digital technologies. He writes about innovative solutions that drive growth and transformation across industry.
Featured on – YOURSTORY | TECHSLING | ELEARNINGINDUSTRY | DATASCIENCECENTRAL | TIMESOFINDIA | MEDIUM | DATAFLOQ



