

Hello, Everyone! Today we are here with another post to further our discussion about basic indexing operations in solr. Solr provides a rich mechanism by which it can absorb documents of varied types such as PDF, word etc. The way it does that is by using Apache Tika Parser.
Uploading Data with Solr Cell using Apache Tika
Solr uses code from the Apache Tika project to provide a framework for incorporating many different file-format parsers such as Apache PDFBox and Apache POI into Solr itself. Working with this framework, Solr’s ExtractingRequestHandler can use Tika to support uploading binary files, including files in popular formats such as Word and PDF, for data extraction and indexing.
When this framework was under development, it was called the Solr Content Extraction Library or CEL; from that abbreviation came this framework’s name: Solr Cell.
If you want to supply your own ContentHandler for Solr to use, you can extend the ExtractingRequestHandler and override the createFactory() method. This factory is responsible for constructing the SolrContentHandler that interacts with Tika, and allows literals to override Tika-parsed values. Set the parameter literalsOverride, which normally defaults to true, to false to append Tika-parsed values to literal values.
Key Solr Cell Concepts
When using the Solr Cell framework, it is helpful to keep the following in mind:
- Tika will automatically attempt to determine the input document type (Word, PDF, HTML) and extract the content appropriately. If you like, you can explicitly specify a MIME type for Tika with the
stream.typeparameter. - Tika works by producing an XHTML stream that it feeds to a SAX ContentHandler. SAX is a common interface implemented for many different XML parsers. For more information, see http://www.saxproject.org/quickstart.html.
- Solr then responds to Tika’s SAX events and creates the fields to index.
- Tika produces metadata such as Title, Subject, and Author according to specifications such as the DublinCore. See http://tika.apache.org/1.17/formats.html for the file types supported.
- Tika adds all the extracted text to the
contentfield. - You can map Tika’s metadata fields to Solr fields.
- You can pass in literals for field values. Literals will override Tika-parsed values, including fields in the Tika metadata object, the Tika content field, and any “captured content” fields.
- You can apply an XPath expression to the Tika XHTML to restrict the content that is produced.
One can use curl to send a sample PDF file via HTTP POST like below:
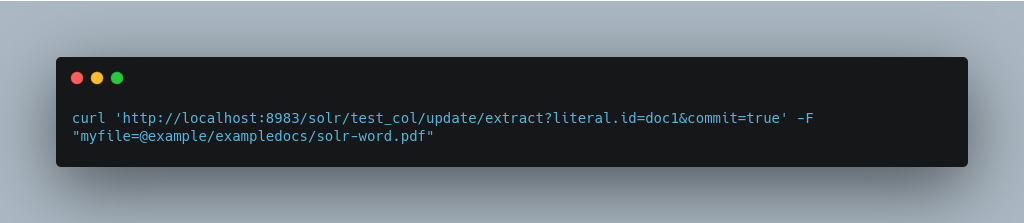
The URL above calls the Extracting Request Handler, uploads the file solr-word.pdf and assigns it the unique ID doc1. Here’s a closer look at the components of this command:
- The
literal.id=doc1parameter provides the necessary unique ID for the document being indexed. - The
commit=true parametercauses Solr to perform a commit after indexing the document, making it immediately searchable. For optimum performance when loading many documents, don’t call the commit command until you are done. - The
-Fflag instructs curl to POST data using the Content-Typemultipart/form-dataand supports the uploading of binary files. The @ symbol instructs curl to upload the attached file. - The argument
myfile=@tutorial.htmlneeds a valid path, which can be absolute or relative.
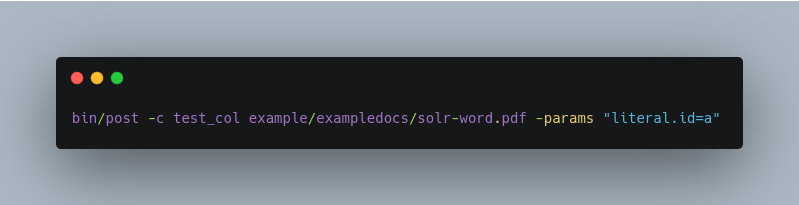
You can also use bin/post to send a PDF file into Solr (without the params, the literal.id parameter would be set to the absolute path to the file):
Now you should be able to execute a query and find that document. You can make a request like:
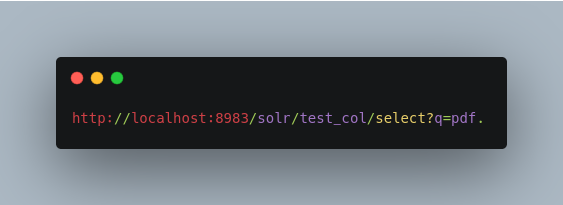
You may notice that although the content of the sample document has been indexed and stored, there are not a lot of metadata fields associated with this document. This is because unknown fields are ignored according to the default parameters configured for the /update/extract handler in solrconfig.xml, and this behavior can be easily changed or overridden. For example, to store and see all metadata and content, execute the following:
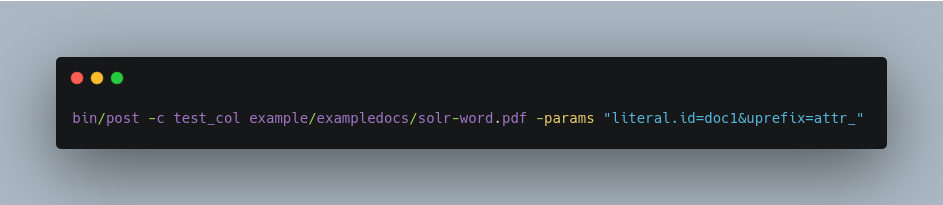
In this command, the uprefix=attr_ parameter causes all generated fields that aren’t defined in the schema to be prefixed with attr_, which is a dynamic field that is stored and indexed.
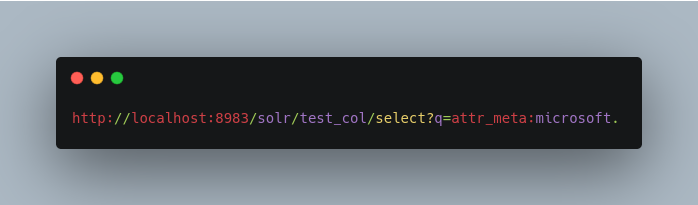
This command allows you to query the document using an attribute, as in:
Solr Cell Input Parameters
capture
Captures XHTML elements with the specified name for a supplementary addition to the Solr document. This parameter can be useful for copying chunks of the XHTML into a separate field. For instance, it could be used to grab paragraphs (<p>) and index them into a separate field. Note that content is still also captured into the overall “content” field.
captureAttrIndexes attributes of the Tika XHTML elements into separate fields, named after the element. If set to true, for example, when extracting from HTML, Tika can return the href attributes in <a> tags as fields named “a”.
commitWithin
Add the document within the specified number of milliseconds.
date.formatsDefines the date format patterns to identify in the documents.
defaultFieldIf the uprefix parameter (see below) is not specified and a field cannot be determined, the default field will be used.
extractOnlyDefault is false. If true, returns the extracted content from Tika without indexing the document. This literally includes the extracted XHTML as a string in the response. When viewing manually, it may be useful to use a response format other than XML to aid in viewing the embedded XHTML tags.
extractOnly
Default is false. If true, returns the extracted content from Tika without indexing the document. This literally includes the extracted XHTML as a string in the response. When viewing manually, it may be useful to use a response format other than XML to aid in viewing the embedded XHTML tags. For an example, see http://wiki.apache.org/solr/TikaExtractOnlyExampleOutput.
extractFormatThe default is xml, but the other option is text. Controls the serialization format of the extract content. The xml format is actually XHTML, the same format that results from passing the -x command to the Tika command line application, while the text format is like that produced by Tika’s -t command. This parameter is valid only if extractOnly is set to true.
fmap.source_fieldMaps (moves) one field name to another. The source_field must be a field in incoming documents, and the value is the Solr field to map to. Example: fmap.content=text causes the data in the content field generated by Tika to be moved to the Solr’s text field.
ignoreTikaExceptionIf true, exceptions found during processing will be skipped. Any metadata available, however, will be indexed.
literal.fieldnamePopulates a field with the name supplied with the specified value for each document. The data can be multivalued if the field is multivalued.
literalsOverride
If true (the default), literal field values will override other values with the same field name. If false, literal values defined with literal.fieldname will be appended to data already in the fields extracted from Tika. If setting literalsOverride to false, the field must be multivalued.
lowernamesValues are true or false. If true, all field names will be mapped to lowercase with underscores, if needed. For example, “Content-Type” would be mapped to “content_type.”
multipartUploadLimitInKBUseful if uploading very large documents, this defines the KB size of documents to allow.
passwordsFileDefines a file path and name for a file of file name to password mappings.
resource.nameSpecifies the optional name of the file. Tika can use it as a hint for detecting a file’s MIME type.
resource.passwordDefines a password to use for a password-protected PDF or OOXML file
tika.configDefines a file path and name to a customized Tika configuration file. This is only required if you have customized your Tika implementation.
uprefixPrefixes all fields that are not defined in the schema with the given prefix. This is very useful when combined with dynamic field definitions. Example: uprefix=ignored_ would effectively ignore all unknown fields generated by Tika given the example schema contains <dynamicField name="ignored_*" type="ignored"/>
xpathWhen extracting, only return Tika XHTML content that satisfies the given XPath expression.
Order of Operations
Here is the order in which the Solr Cell framework, using the Extracting Request Handler and Tika, processes its input.
- Tika generates fields or passes them in as literals specified by
literal.<fieldname>=<value>. IfliteralsOverride=false, literals will be appended as multi-value to the Tika-generated field. - If
lowernames=true, Tika maps fields to lowercase. - Tika applies the mapping rules specified by
fmap.source=targetparameters. - If
uprefixis specified, any unknown field names are prefixed with that value, else ifdefaultFieldis specified, any unknown fields are copied to the default field.
Configuring the Solr ExtractingRequestHandler
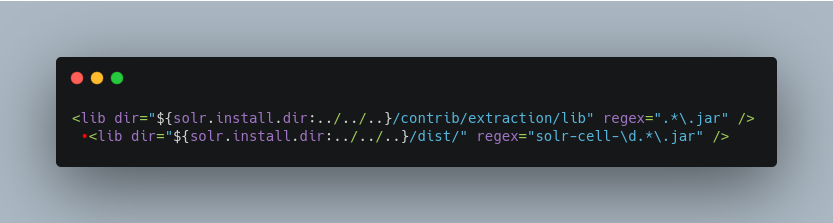
Add the following dependencies in solrconfig.xml file.
You can then configure the ExtractingRequestHandler in solrconfig.xml.
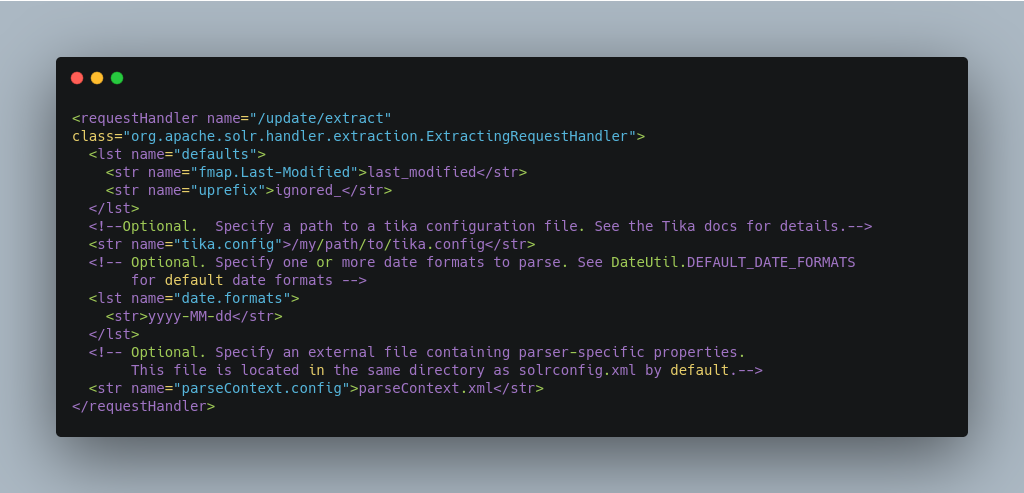
In the defaults section, we are mapping Tika’s Last-Modified Metadata attribute to a field named last_modified. We are also telling it to ignore undeclared fields. These are all overridden parameters.
The tika.config entry points to a file containing a Tika configuration. The date.formats allows you to specify various java.text.SimpleDateFormats date formats for working with transforming extracted input to a Date. Solr comes configured with the following date formats (see the DateUtil in Solr):
yyyy-MM-dd’T’HH:mm:ss’Z'yyyy-MM-dd’T’HH:mm:ssyyyy-MM-ddyyyy-MM-dd hh:mm:ssyyyy-MM-dd HH:mm:ssEEE MMM d hh:mm:ss z yyyyEEE, dd MMM yyyy HH:mm:ss zzzEEEE, dd-MMM-yy HH:mm:ss zzzEEE MMM d HH:mm:ss yyyy
Parser-Specific Properties
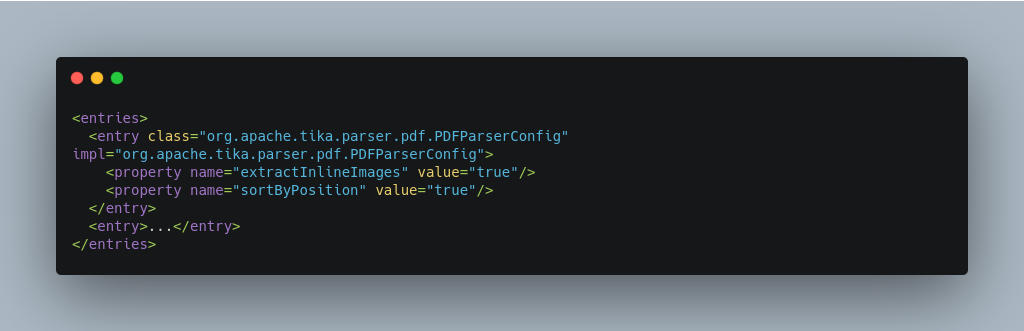
Parsers used by Tika may have specific properties to govern how data is extracted. For instance, when using the Tika library from a Java program, the PDFParserConfig class has a method setSortByPosition(boolean) that can extract vertically oriented text. To access that method via configuration with the ExtractingRequestHandler, one can add the parseContext.config property to the solrconfig.xml file (see above) and then set properties in Tika’s PDFParserConfig as below. Consult the Tika Java API documentation for configuration parameters that can be set for any particular parsers that require this level of control.
Multi-Core Configuration
For a multi-core configuration, you can specify sharedLib='lib' in the <solr/> section of solr.xml and place the necessary jar files there.
Indexing Encrypted Documents with the ExtractingUpdateRequestHandler
The ExtractingRequestHandler will decrypt encrypted files and index their content if you supply a password in either resource.password on the request, or in a passwordsFile file.
In the case of passwordsFile, the file supplied must be formatted so there is one line per rule. Each rule contains a file name regular expression, followed by “=”, then the password in clear-text. Because the passwords are in clear-text, the file should have strict access restrictions.
Solr Cell Examples
Metadata Created by Tika
As mentioned before, Tika produces metadata about the document. Metadata describes different aspects of a document, such as the author’s name, the number of pages, the file size, and so on. The metadata produced depends on the type of document submitted. For instance, PDFs have different metadata than Word documents do.
In addition to Tika’s metadata, Solr adds the following metadata (defined in ExtractingMetadataConstants):
stream_name
The name of the Content Stream as uploaded to Solr. Depending on how the file is uploaded, this may or may not be set.
stream_source_infoAny source info about the stream. (See the section on Content Streams later in this section.)
stream_sizeThe size of the stream in bytes.
stream_content_typeThe content type of the stream, if available.
Examples of Uploads Using the Extracting Request Handler
Capture and Mapping
The command below captures <div> tags separately, and then maps all the instances of that field to a dynamic field named foo_t.
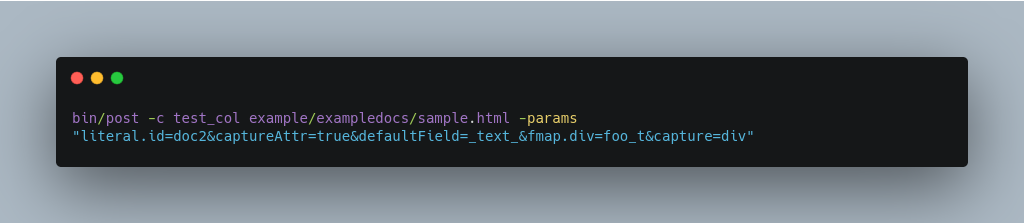
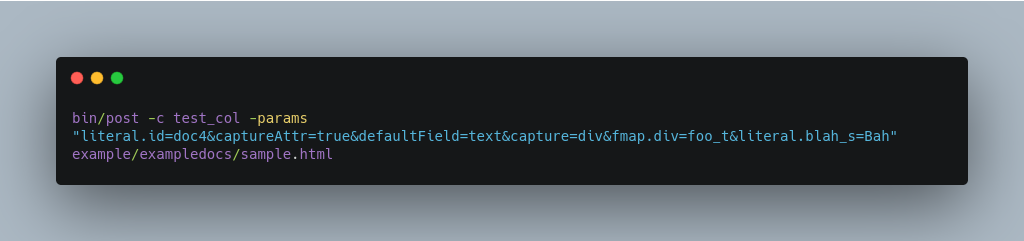
Using Literals to Define Your Own Metadata
To add in your own metadata, pass in the literal parameter along with the file:
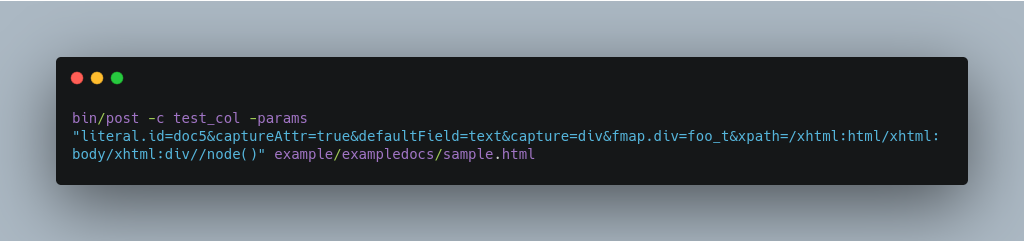
XPath Expressions
The example below passes in an XPath expression to restrict the XHTML returned by Tika:
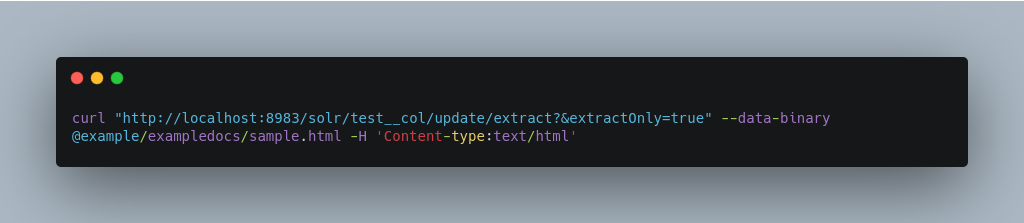
Extracting Data without Indexing It
Solr allows you to extract data without indexing. You might want to do this if you’re using Solr solely as an extraction server or if you’re interested in testing Solr extraction.
The example below sets the extractOnly=true parameter to extract data without indexing it.
The output includes XML generated by Tika (and further escaped by Solr’s XML) using a different output format to make it more readable (-out yes instructs the tool to echo Solr’s output to the console):
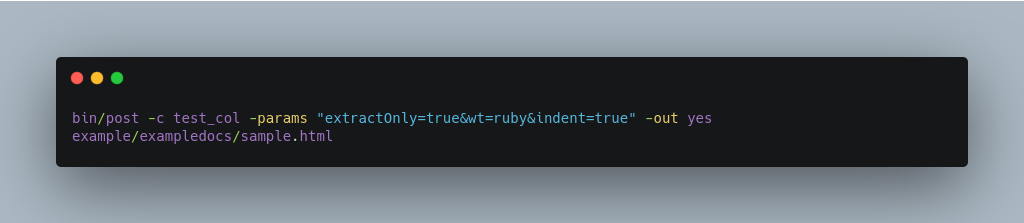
Sending Documents to Solr with a POST
The example below streams the file as the body of the POST, which does not, then, provide information to Solr about the name of the file.
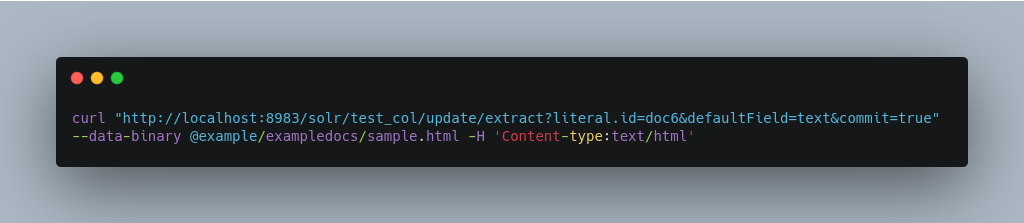
Sending Documents to Solr with Solr Cell and SolrJ
SolrJ is a Java client that you can use to add documents to the index, update the index, or query the index. You’ll find more information on SolrJ in Client APIs.
Here’s an example of using Solr Cell and SolrJ to add documents to a Solr index.
First, let’s use SolrJ to create a new SolrClient, then we’ll construct a request containing a ContentStream (essentially a wrapper around a file) and sent it to Solr:
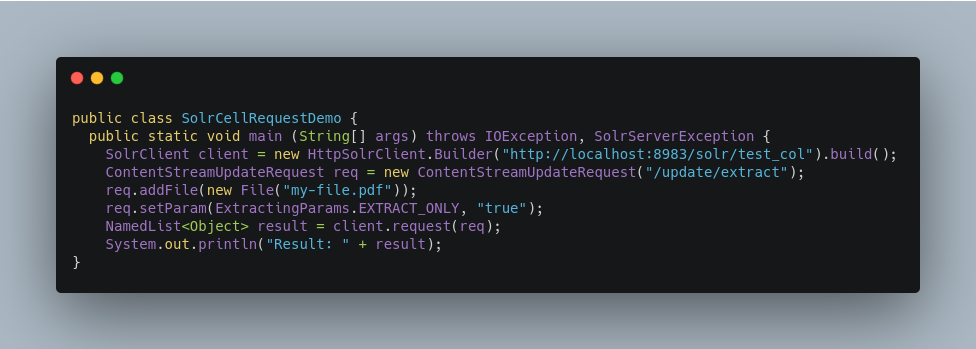
The sample code above calls the extract command, but you can easily substitute other commands that are supported by Solr Cell. The key class to use is the ContentStreamUpdateRequest, which makes sure the ContentStreams are set properly. SolrJ takes care of the rest.
Note that the ContentStreamUpdateRequest is not just specific to Solr Cell. You can send CSV to the CSV Update handler and to any other Request Handler that works with Content Streams for updates.
So, this is it for today. Stay tuned for another post.

Manoj Kumar is a seasoned Digital Marketing Manager and passionate Tech Blogger with deep expertise in SEO, AI trends, and emerging digital technologies. He writes about innovative solutions that drive growth and transformation across industry.
Featured on – YOURSTORY | TECHSLING | ELEARNINGINDUSTRY | DATASCIENCECENTRAL | TIMESOFINDIA | MEDIUM | DATAFLOQ



