

Hello Everyone! Today I would like to discuss a very important aspect about Apache Solr. To perform any basic search operation, we need an index. The index of apache solr rests in terms of a document which is basically a set of fields having certain values. Hence, indexing operation in solr becomes very crucial in building an application. Today, we will discuss the process of indexing: adding content to a Solr index and, if necessary, modifying that content or deleting it.
A Solr index can accept data from many different sources, including XML files, comma-separated value (CSV) files, data extracted from tables in a database, and files in common file formats such as Microsoft Word or PDF.
Here are the three most common ways of loading data into a Solr index:
- Using the Solr Cell framework built on Apache Tika for ingesting binary files or structured files such as Office, Word, PDF, and other proprietary formats.
- Uploading XML files by sending HTTP requests to the Solr server from any environment where such requests can be generated.
- Writing a custom Java application to ingest data through Solr’s Java Client API (which is described in more detail in Client APIs). Using the Java API may be the best choice if you’re working with an application, such as a Content Management System (CMS), that offers a Java API.
Regardless of the method used to ingest data, there is a common basic data structure for data being fed into a Solr index: a document containing multiple fields, each with a name and containing content, which may be empty. One of the fields is usually designated as a unique ID field (analogous to a primary key in a database), although the use of a unique ID field is not strictly required by Solr. If the field name is defined in the Schema that is associated with the index, then the analysis steps associated with that field will be applied to its content when the content is tokenized. Fields that are not explicitly defined in the Schema will either be ignored or mapped to a dynamic field definition (see Documents, Fields, and Schema Design) if one matching the field name exists.
Introduction
Using POST Tool
Solr includes a simple command-line tool for POSTing various types of content to a Solr server.
To run it, open a window and enter:
This will contact the server at localhost:8983. Specifying the collection/core name is mandatory.
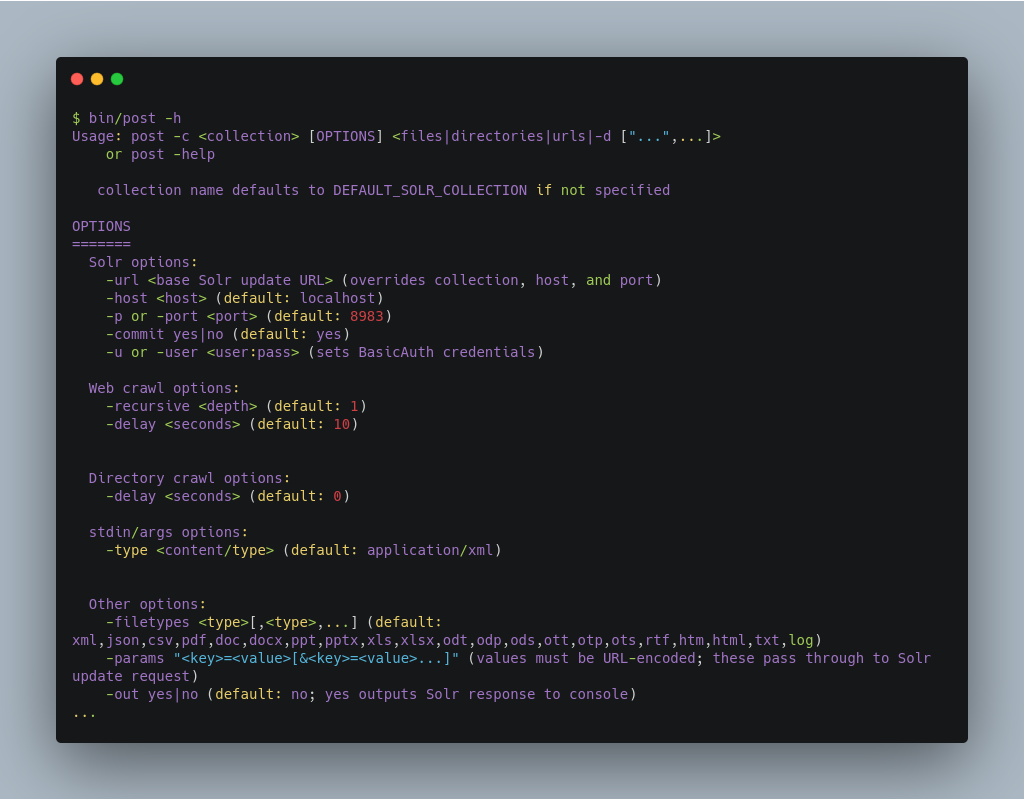
Using the bin/post tool
The basic usage of bin/post is as below:
Basic indexing operations
Indexing XML
Add all documents with file extension .xml to collection or core named test_col.
Send XML arguments to delete a document from test_col.
Indexing CSV
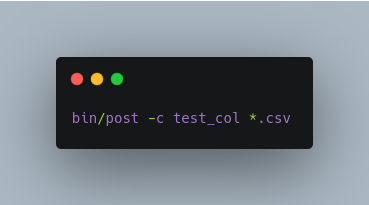
Index all CSV files into test_col
Index a tab-separated file into test_col:
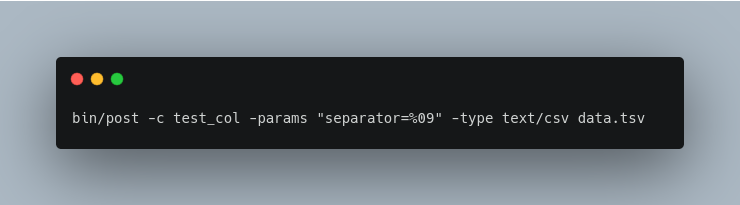
-type) parameter is required to treat the file as the proper type, otherwise, it will be ignored and a WARNING logged as it does not know what type of content a .csv file is. The CSV handler supports the separator parameter, and is passed through using the -params setting.
Indexing JSON
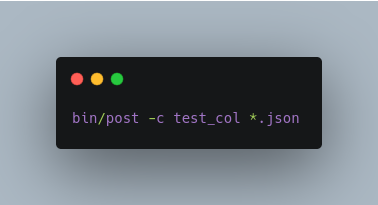
Index all JSON files into test_col
Indexing Rich Documents (PDF, Word, HTML, etc.)
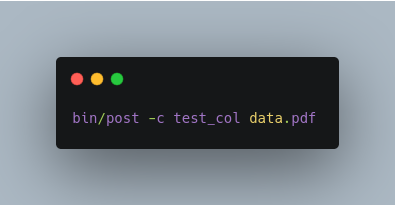
Index a PDF file into test_col
Automatically detect content types in a folder, and recursively scan it for documents for indexing into test_col.
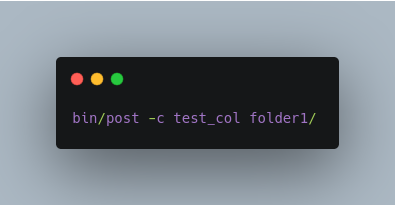
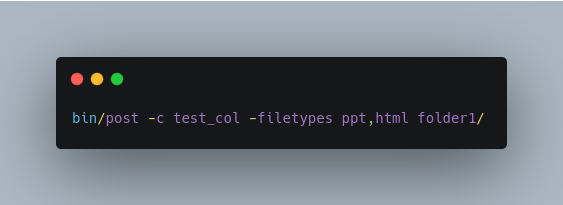
Automatically detect content types in a folder, but limit it to PPT and HTML files and index into test_col
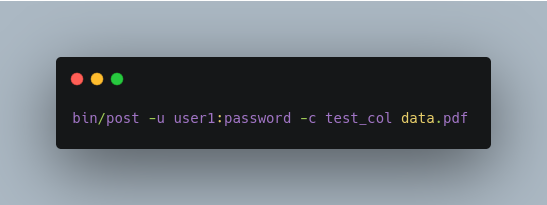
Indexing to a Password Protected Solr (Basic Auth):

So, this is it for today about indexing operations in solr. More will be covered about the same in the next post.
Index a PDF as the user “user1” with password “password”:
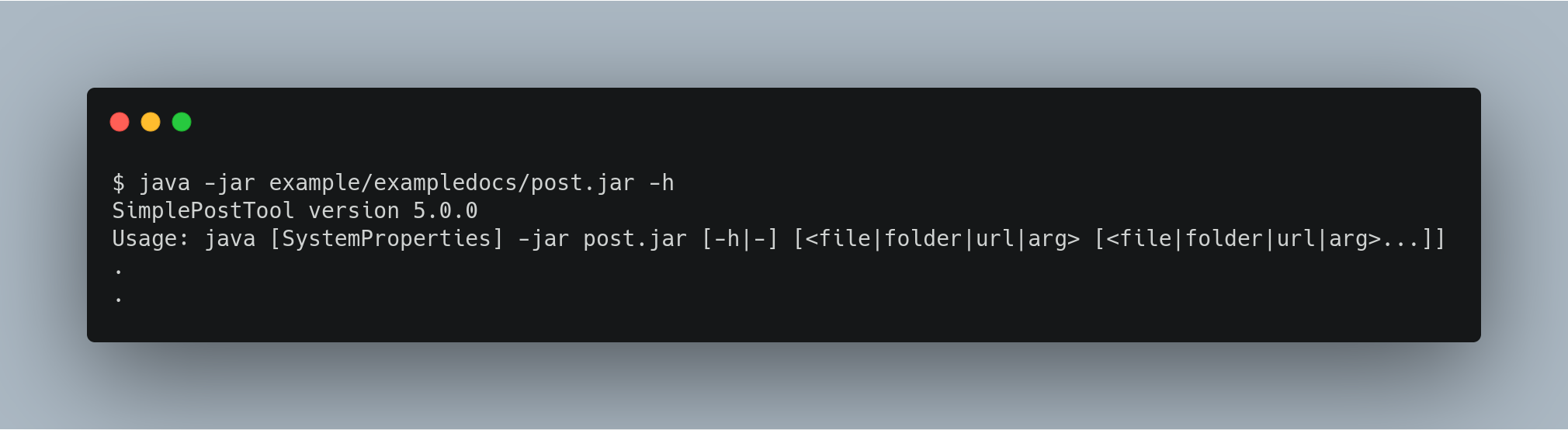
SimplePostTool
The bin/post script currently delegates to a standalone Java program called SimplePostTool.
This tool, bundled into an executable JAR, can be run directly using java -jar test_col/post.jar.
Uploading Data with Index Handlers
Index Handlers are Request Handlers designed to add, delete and update documents to the index. In addition to having plugins for importing rich documents using Tika or from structured data sources using the Data Import Handler, Solr natively supports indexing structured documents in XML, CSV and JSON.
The recommended way to configure and use request handlers is with path-based names that map to paths in the request url. However, request handlers can also be specified with the qt (query type) parameter if the requestDispatcher is appropriately configured. It is possible to access the same handler using more than one name, which can be useful if you wish to specify different sets of default options.
A single unified update request handler supports XML, CSV, JSON, and java bin update requests, delegating to the appropriate ContentStreamLoader based on the Content-Type of the ContentStream.
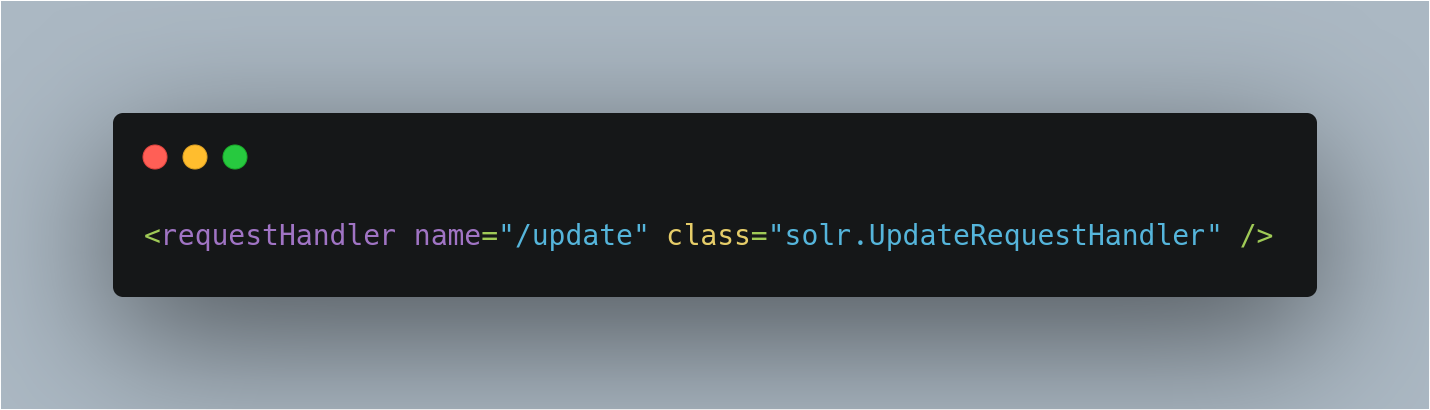
UpdateRequestHandler Configuration
The default configuration file has the update request handler configured by default.
Adding Documents
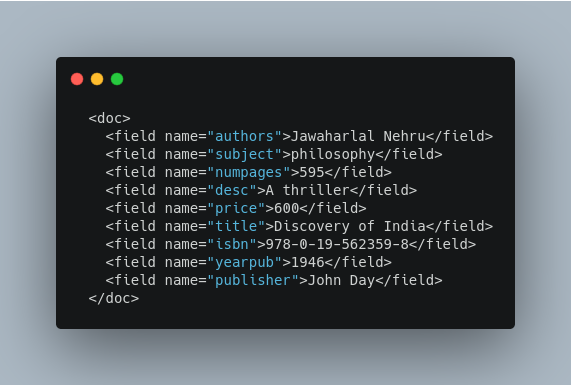
Adding XML documents
The XML schema recognized by the update handler for adding documents is very straightforward:
- The
<add>element introduces one more documents to be added. - The
<doc>element introduces the fields making up a document. - The
<field>element presents the content for a specific field.
For example:
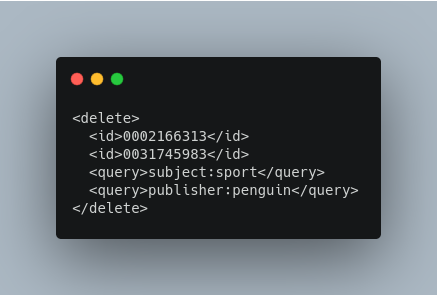
Delete Operations
Documents can be deleted from the index in two ways. “Delete by ID” deletes the document with the specified ID, and can be used only if a UniqueID field has been defined in the schema. “Delete by Query” deletes all documents matching a specified query, although commitWithin is ignored for a Delete by Query. A single delete message can contain multiple delete operations.
Rollback Operations
The rollback command rolls back all add and deletes made to the index since the last commit. It neither calls any event listeners nor creates a new searcher. Its syntax is simple: <rollback/>.
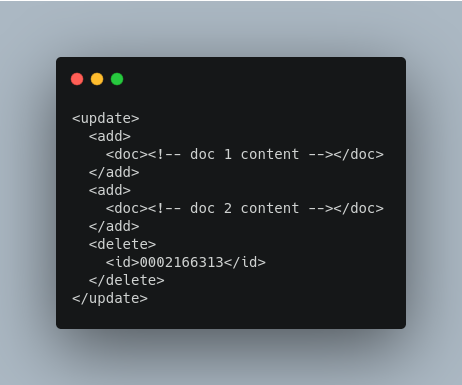
Grouping Operations
You can post several commands in a single XML file by grouping them with the surrounding <update> element.
Using curl to Perform Updates
You can use the curl utility to perform any of the above commands, using its --data-binary option to append the XML message to the curl command, and generating a HTTP POST request. For example:
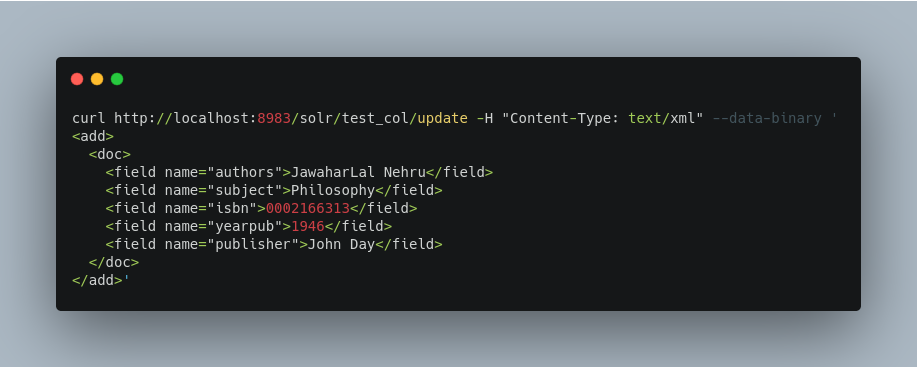
For posting XML messages contained in a file, you can use the alternative form:
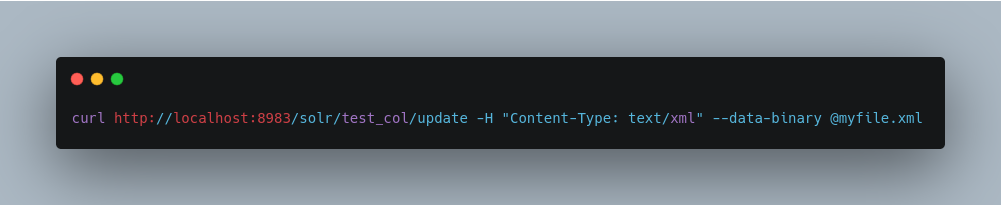
Short requests can also be sent using a HTTP GET command, if enabled in RequestDispatcher in SolrConfig element, URL-encoding the request, as in the following. Note the escaping of “<” and “>”:
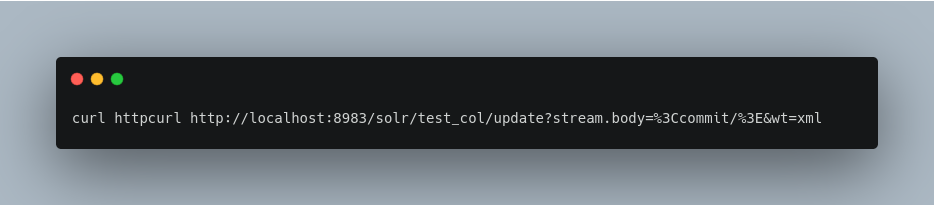
JSON Formatted Index Updates
Solr can accept JSON that conforms to a defined structure, or can accept arbitrary JSON-formatted documents. If sending arbitrarily formatted JSON, there are some additional parameters that need to be sent with the update request, described below in the section Transforming and Indexing Custom JSON.
Solr-Style JSON
JSON formatted update requests may be sent to Solr’s /update handler using Content-Type: application/json or Content-Type: text/json.
JSON formatted updates can take 3 basic forms, described in-depth below:
- A single document to add, expressed as a top level JSON Object. To differentiate this from a set of commands, the
json.command=falserequest parameter is required. - A list of documents to add, expressed as a top level JSON Array containing a JSON Object per document.
- A sequence of update commands, expressed as a top level JSON Object (aka: Map).
Adding a Single JSON Document
/update/json/docs path: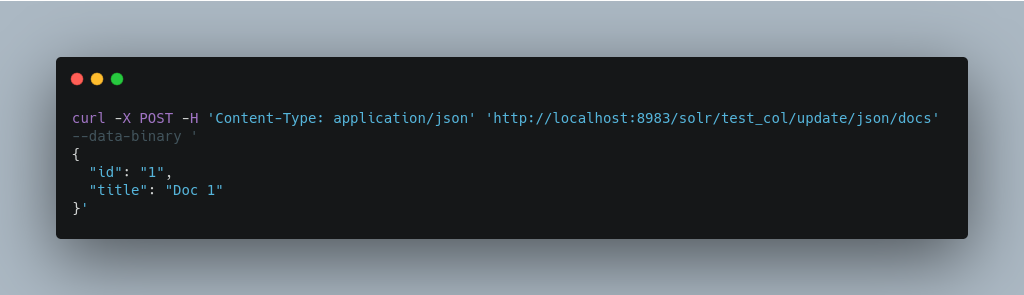
Adding Multiple JSON Documents
Adding multiple documents at one time via JSON can be done via a JSON Array of JSON Objects, where each object represents a document:
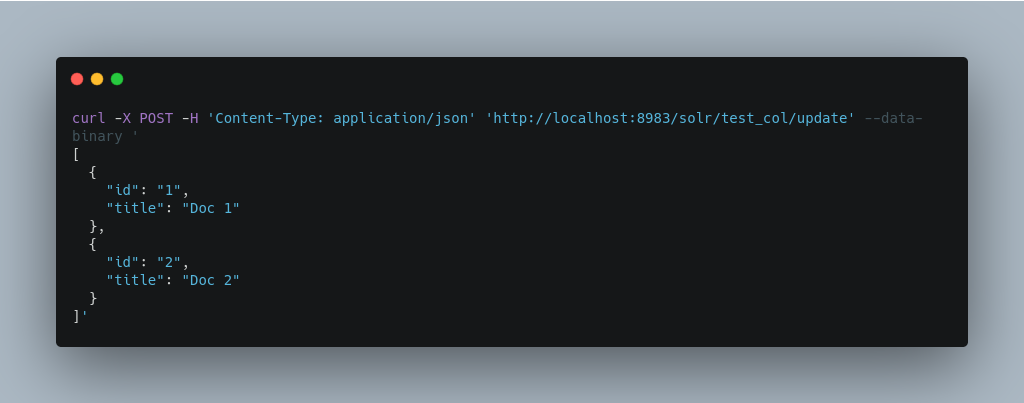
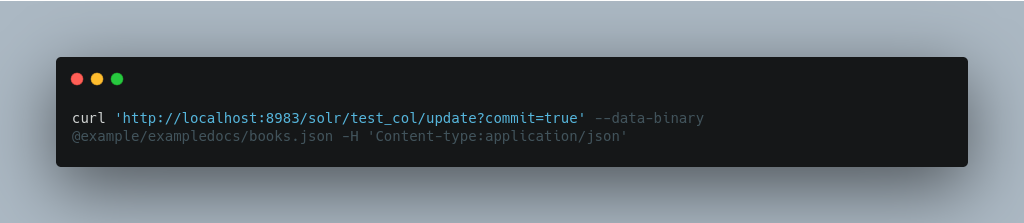
A sample JSON file is provided at test_col/books.json and contains an array of objects that you can add to the Solr test_col example:
So, this is it for today about indexing operations in solr. More will be covered about the same in the next post.

Manoj Kumar is a seasoned Digital Marketing Manager and passionate Tech Blogger with deep expertise in SEO, AI trends, and emerging digital technologies. He writes about innovative solutions that drive growth and transformation across industry.
Featured on – YOURSTORY | TECHSLING | ELEARNINGINDUSTRY | DATASCIENCECENTRAL | TIMESOFINDIA | MEDIUM | DATAFLOQ



