

Introduction
Hi folks! We are back with another post. Today we will discuss in detail a very important feature of solr that is invariably used in any large enterprise applications. When we render a response from a database, we receive a large number of results based on the query fired by the user. This generates the need to be specific with respect to how many records need to be displayed to the user at once. To facilitate this, solr has an implementation called “Pagination”. (https://glasshousefarms.org/)
What is Pagination?
In many applications, the UI for these sorted results are displayed to the user in “pages” containing a fixed number of matching results, and users don’t typically look at results past the first few pages worth of results.
In Solr, this basic paginated searching is supported using the start and rows parameters, and performance of this common behavior can be tuned by utilizing the queryResultCache and adjusting the queryResultWindowSize configuration options based on your expected page sizes.
Basics of Pagination
If an index modification (such as adding or removing documents) which affects the sequence of ordered documents matching a query occurs in between two requests from a client for subsequent pages of results, then it is possible that these modifications can result in the same document being returned on multiple pages, or documents being “skipped” as the result set shrinks or grows. In some situations, the results of a Solr search are not destined for a simple paginated user interface.
When you wish to fetch a very large number of sorted results from Solr to feed into an external system, using very large values for the start or rows parameters can be very inefficient. Pagination using start and rows not only require Solr to compute (and sort) in memory all of the matching documents that should be fetched for the current page, but also all of the documents that would have appeared on previous pages. While a request for start=0&rows=1000000 maybe obviously inefficient because it requires Solr to maintain & sort in memory a set of 1 million documents, likewise a request for start=999000&rows=1000 is equally inefficient for the same reasons. Solr can’t compute which matching document is the 999001st result in sorted order, without first determining what the first 999000 matching sorted results are. If the index is distributed, which is common when running in SolrCloud mode, then 1 million documents are retrieved from each shard. For a ten shard index, ten million entries must be retrieved and sorted to figure out the 1000 documents that match those query parameters.
Understanding Cursors
As an alternative to increasing the “start” parameter to request subsequent pages of sorted results, Solr supports using a “Cursor” to scan through results. Cursors in Solr are a logical concept that doesn’t involve caching any state information on the server. Instead, the sort values of the last document returned to the client are used to compute a “mark” representing a logical point in the ordered space of sort values. That “mark” can be specified in the parameters of subsequent requests to tell Solr where to continue.
To use a cursor with Solr, specify a cursorMark parameter with the value of *. You can think of this being analogous to start=0 as a way to tell Solr “start at the beginning of my sorted results” except that it also informs Solr that you want to use a Cursor. In addition to returning the top N sorted results (where you can control N using the rows parameter) the Solr response will also include an encoded String named nextCursorMark. You then take the nextCursorMark String value from the response, and pass it back to Solr as the cursorMark parameter for your next request. You can repeat this process until you’ve fetched as many docs as you want, or until the nextCursorMark returned matches the cursorMark you’ve already specified — indicating that there are no more results.
Example:
Fetch All Docs
The pseudo-code shown here shows the basic logic involved in fetching all documents matching a query using a cursor:
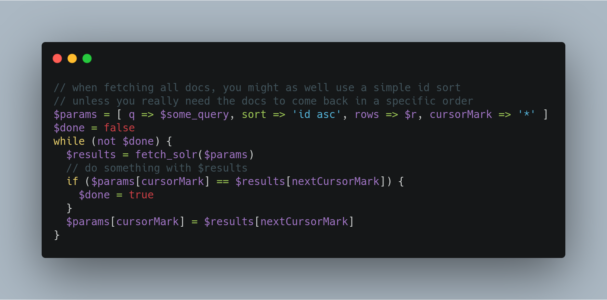
If you wanted to do this by hand using curl, the sequence of requests would look something like this:
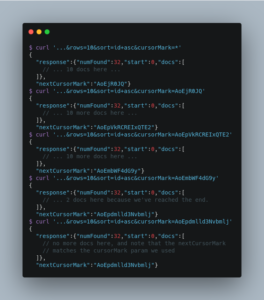
Because Cursor requests are stateless, and the cursorMark values encapsulate the absolute sort values of the last document returned from a search, it’s possible to “continue” fetching additional results from a cursor that has already reached its end. If new documents are added (or existing documents are updated) to the end of the results.
You can think of this as similar to using something like “tail -f” in Unix. The most common examples of how this can be useful is when you have a “timestamp” field recording when a document has been added/updated in your index. Client applications can continuously poll a cursor using a sort=timestamp asc, id asc for documents matching a query, and always be notified when a document is added or updated matching the request criteria.
Another common example is when you have uniqueKey values that always increase as new documents are created, and you can continuously poll a cursor using sort=id asc to be notified about new documents.
So, this is it about Pagination in solr. We will be back with another post on solr very soon.

Manoj Kumar is a seasoned Digital Marketing Manager and passionate Tech Blogger with deep expertise in SEO, AI trends, and emerging digital technologies. He writes about innovative solutions that drive growth and transformation across industry.
Featured on – YOURSTORY | TECHSLING | ELEARNINGINDUSTRY | DATASCIENCECENTRAL | TIMESOFINDIA | MEDIUM | DATAFLOQ


